# Séance 8: TP3 - Régression & Optimisation
::: {.callout-note icon=false}
## Informations de la séance
- **Type**: Travaux Pratiques
- **Durée**: 2h
- **Objectifs**: Obj6, Obj7
:::
## Introduction
Dans ce TP, nous allons mettre en pratique les concepts de régression vus en cours. Nous travaillerons sur un dataset réel pour prédire les prix de maisons, en comparant différents modèles de régression et en optimisant leurs hyperparamètres.
**Objectifs du TP:**
1. Prétraiter des données pour la régression
2. Implémenter et comparer Linear, Ridge, Lasso, ElasticNet, SVR
3. Optimiser les hyperparamètres avec CV
4. Évaluer avec métriques multiples (MAE, RMSE, R²)
5. Interpréter et visualiser les résultats
## 1. Chargement et Exploration du Dataset
Nous utilisons le **Boston Housing Dataset** (ou California Housing si Boston non disponible).
```{python}
#| echo: true
#| eval: true
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.datasets import fetch_california_housing
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
# Chargement
california = fetch_california_housing()
X, y = california.data, california.target
# DataFrame pour exploration
df = pd.DataFrame(X, columns=california.feature_names)
df['MedHouseVal'] = y
print("=" * 70)
print("DATASET: CALIFORNIA HOUSING")
print("=" * 70)
print(f"\nShape: {X.shape}")
print(f"Features: {california.feature_names}")
print(f"\nDescription du target (prix médian en 100k$):")
print(df['MedHouseVal'].describe())
# Statistiques descriptives
print("\n" + "=" * 70)
print("STATISTIQUES DESCRIPTIVES")
print("=" * 70)
print(df.describe().T)
# Vérifier les valeurs manquantes
print(f"\nValeurs manquantes par feature:")
print(df.isnull().sum())
# Visualisations
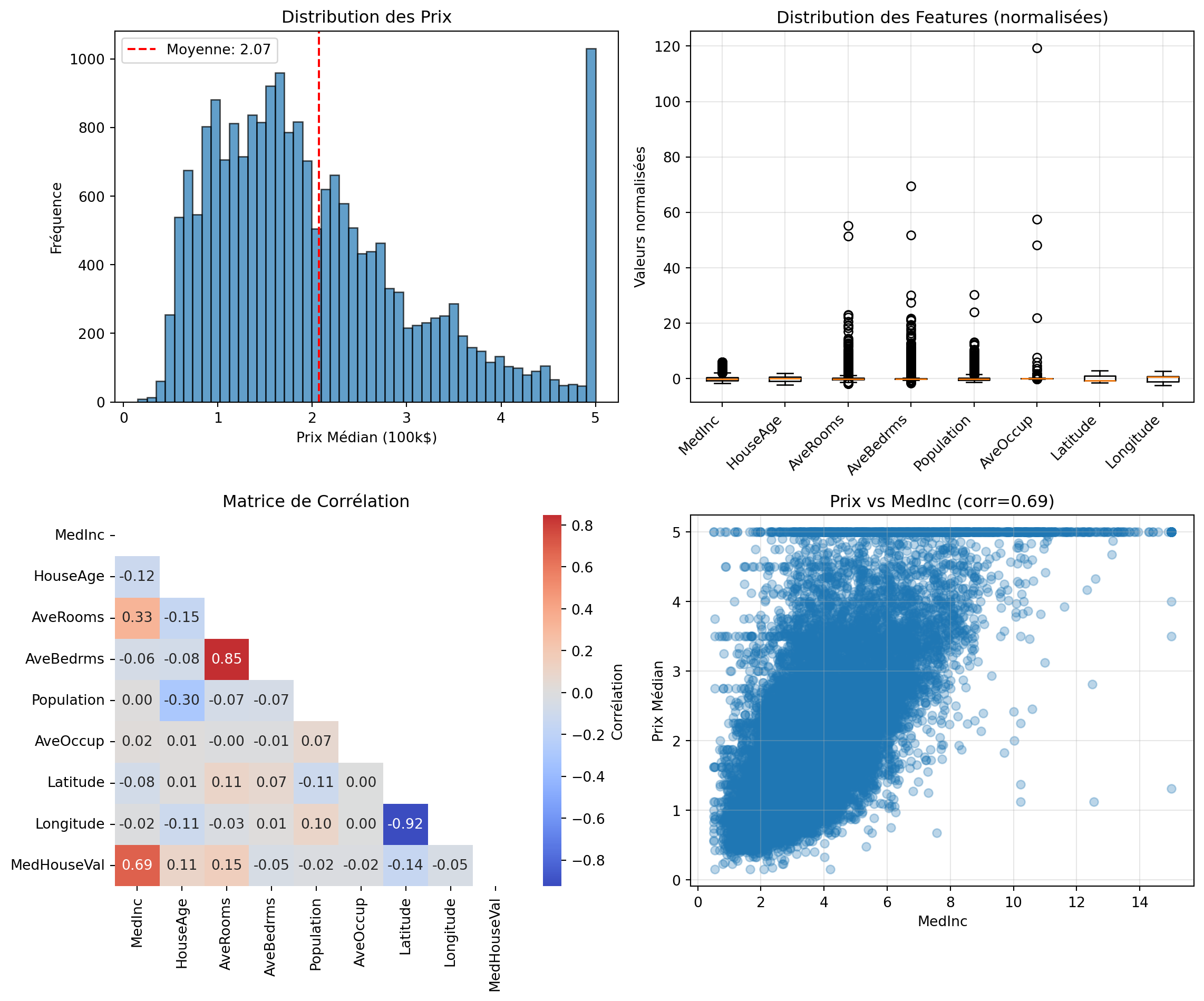
fig, axes = plt.subplots(2, 2, figsize=(12, 10))
# Distribution du target
axes[0, 0].hist(y, bins=50, edgecolor='black', alpha=0.7)
axes[0, 0].set_xlabel('Prix Médian (100k$)')
axes[0, 0].set_ylabel('Fréquence')
axes[0, 0].set_title('Distribution des Prix')
axes[0, 0].axvline(y.mean(), color='red', linestyle='--', label=f'Moyenne: {y.mean():.2f}')
axes[0, 0].legend()
# Boxplot des features (normalisées pour comparaison)
df_normalized = (df - df.mean()) / df.std()
axes[0, 1].boxplot([df_normalized[col] for col in california.feature_names],
labels=california.feature_names, vert=True)
axes[0, 1].set_xticklabels(california.feature_names, rotation=45, ha='right')
axes[0, 1].set_ylabel('Valeurs normalisées')
axes[0, 1].set_title('Distribution des Features (normalisées)')
axes[0, 1].grid(alpha=0.3)
# Matrice de corrélation
corr_matrix = df.corr()
mask = np.triu(np.ones_like(corr_matrix, dtype=bool))
sns.heatmap(corr_matrix, mask=mask, annot=True, fmt='.2f', cmap='coolwarm',
center=0, ax=axes[1, 0], cbar_kws={'label': 'Corrélation'})
axes[1, 0].set_title('Matrice de Corrélation')
# Scatter: Feature la plus corrélée avec target
corr_with_target = corr_matrix['MedHouseVal'].drop('MedHouseVal').abs().sort_values(ascending=False)
best_feature = corr_with_target.index[0]
axes[1, 1].scatter(df[best_feature], df['MedHouseVal'], alpha=0.3)
axes[1, 1].set_xlabel(best_feature)
axes[1, 1].set_ylabel('Prix Médian')
axes[1, 1].set_title(f'Prix vs {best_feature} (corr={corr_matrix.loc[best_feature, "MedHouseVal"]:.2f})')
axes[1, 1].grid(alpha=0.3)
plt.tight_layout()
plt.show()
print("\n" + "=" * 70)
print("CORRÉLATIONS AVEC LE TARGET")
print("=" * 70)
print(corr_with_target)
```
### Exercice 1.1: Analyse Exploratoire
**Questions:**
1. Quelle feature est la plus corrélée avec le prix?
2. Y a-t-il des features fortement corrélées entre elles? (Multicolinéarité potentielle?)
3. La distribution du target est-elle gaussienne? Quel traitement pourrait être appliqué si non?
4. Identifiez des outliers potentiels
::: {.callout-note collapse="true"}
## Solution Exercice 1.1
```{python}
#| echo: true
#| eval: true
print("=" * 70)
print("ANALYSE EXPLORATOIRE - RÉPONSES")
print("=" * 70)
# 1. Feature la plus corrélée
print(f"\n1. Feature la plus corrélée avec le prix:")
print(f" → {best_feature} (corrélation = {corr_matrix.loc[best_feature, 'MedHouseVal']:.3f})")
# 2. Multicolinéarité
print(f"\n2. Paires de features fortement corrélées (|corr| > 0.7):")
corr_pairs = []
for i in range(len(corr_matrix.columns)):
for j in range(i+1, len(corr_matrix.columns)):
if i != j:
corr_val = corr_matrix.iloc[i, j]
if abs(corr_val) > 0.7:
corr_pairs.append((corr_matrix.columns[i], corr_matrix.columns[j], corr_val))
if corr_pairs:
for feat1, feat2, corr_val in corr_pairs:
print(f" • {feat1} <-> {feat2}: {corr_val:.3f}")
else:
print(" → Aucune multicolinéarité forte détectée")
# 3. Distribution du target
from scipy import stats
shapiro_stat, shapiro_p = stats.shapiro(y[:1000]) # Test sur échantillon
print(f"\n3. Test de normalité (Shapiro-Wilk):")
print(f" Statistique: {shapiro_stat:.4f}, p-value: {shapiro_p:.4e}")
if shapiro_p < 0.05:
print(" → Distribution NON gaussienne (p < 0.05)")
print(" Traitements possibles:")
print(" • Transformation log(y)")
print(" • Transformation Box-Cox")
print(" • Utiliser des modèles robustes aux distributions non-gaussiennes")
else:
print(" → Distribution gaussienne (p >= 0.05)")
# Skewness et Kurtosis
skewness = stats.skew(y)
kurtosis = stats.kurtosis(y)
print(f" Asymétrie (Skewness): {skewness:.3f}")
print(f" Aplatissement (Kurtosis): {kurtosis:.3f}")
# 4. Outliers
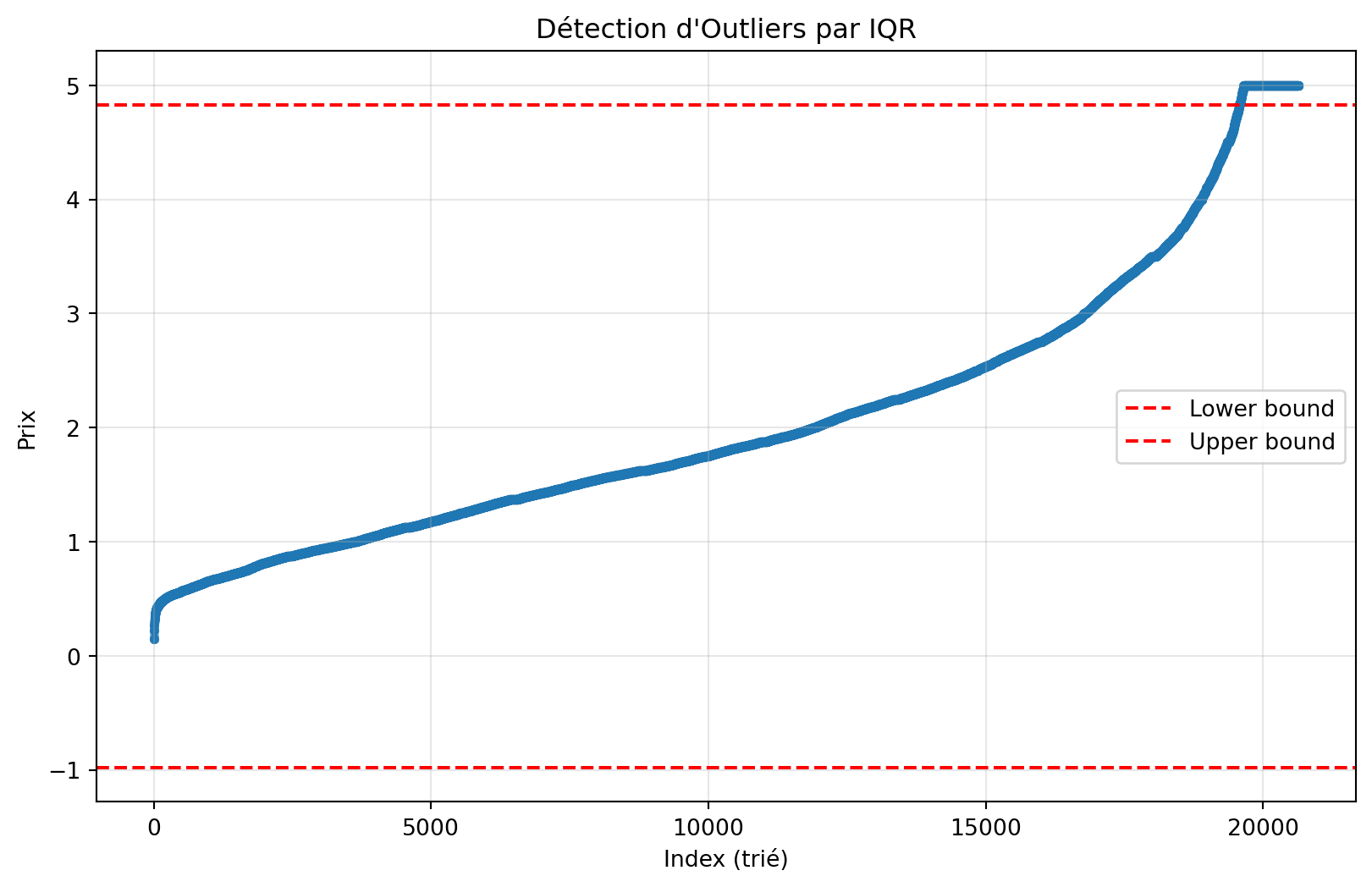
print(f"\n4. Détection d'outliers:")
Q1 = df['MedHouseVal'].quantile(0.25)
Q3 = df['MedHouseVal'].quantile(0.75)
IQR = Q3 - Q1
lower_bound = Q1 - 1.5 * IQR
upper_bound = Q3 + 1.5 * IQR
outliers = df[(df['MedHouseVal'] < lower_bound) | (df['MedHouseVal'] > upper_bound)]
print(f" Intervalle IQR: [{Q1:.2f}, {Q3:.2f}]")
print(f" Bornes: [{lower_bound:.2f}, {upper_bound:.2f}]")
print(f" Nombre d'outliers: {len(outliers)} ({len(outliers)/len(df)*100:.1f}%)")
# Visualisation des outliers
fig, ax = plt.subplots(figsize=(10, 6))
ax.scatter(range(len(y)), np.sort(y), alpha=0.5, s=10)
ax.axhline(lower_bound, color='red', linestyle='--', label='Lower bound')
ax.axhline(upper_bound, color='red', linestyle='--', label='Upper bound')
ax.set_xlabel('Index (trié)')
ax.set_ylabel('Prix')
ax.set_title('Détection d\'Outliers par IQR')
ax.legend()
ax.grid(alpha=0.3)
plt.show()
```
**Conclusions typiques:**
1. **MedInc** (revenu médian) généralement le plus corrélé (~0.68)
2. Multicolinéarité possible → considérer Ridge/ElasticNet
3. Distribution souvent légèrement asymétrique → transformation log possible
4. Quelques outliers mais acceptable (<5%)
:::
## 2. Prétraitement et Split
```{python}
#| echo: true
#| eval: true
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
# Split train/test (80/20)
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42
)
print("=" * 70)
print("SPLIT DES DONNÉES")
print("=" * 70)
print(f"Train set: {X_train.shape}")
print(f"Test set: {X_test.shape}")
# Standardisation (importante pour Ridge, Lasso, SVR)
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)
print("\nStandardisation:")
print(f"Mean (train): {X_train_scaled.mean(axis=0)}") # Devrait être ~0
print(f"Std (train): {X_train_scaled.std(axis=0)}") # Devrait être ~1
# Vérification
print(f"\nVérification après scaling:")
print(f" Mean proche de 0: {np.allclose(X_train_scaled.mean(axis=0), 0, atol=1e-10)}")
print(f" Std proche de 1: {np.allclose(X_train_scaled.std(axis=0), 1, atol=1e-2)}")
```
::: {.callout-warning}
## Importance de la Standardisation
**Pourquoi standardiser?**
- Ridge/Lasso: Pénalisation équitable des coefficients
- SVR: Sensible à l'échelle des features
- Convergence plus rapide des algorithmes itératifs
**Quand ne PAS standardiser?**
- Arbres de décision / Random Forest (invariants aux transformations monotones)
- Régression linéaire simple (si pas de régularisation)
**Règle:** Toujours fit sur train, transform sur test (éviter data leakage)
:::
## 3. Modèles de Base
### Exercice 3.1: Régression Linéaire Simple
Entraînez une régression linéaire et évaluez-la.
**Instructions:**
1. Créez et entraînez le modèle
2. Prédisez sur train et test
3. Calculez MAE, RMSE, R² pour les deux ensembles
4. Affichez les 5 coefficients les plus importants
5. Visualisez prédictions vs vraies valeurs
::: {.callout-note collapse="true"}
## Solution Exercice 3.1
```{python}
#| echo: true
#| eval: true
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_absolute_error, mean_squared_error, r2_score
print("=" * 70)
print("RÉGRESSION LINÉAIRE SIMPLE")
print("=" * 70)
# 1. Entraînement
model_lr = LinearRegression()
model_lr.fit(X_train_scaled, y_train)
# 2. Prédictions
y_train_pred = model_lr.predict(X_train_scaled)
y_test_pred = model_lr.predict(X_test_scaled)
# 3. Métriques
def evaluate_model(y_true, y_pred, dataset_name=""):
mae = mean_absolute_error(y_true, y_pred)
mse = mean_squared_error(y_true, y_pred)
rmse = np.sqrt(mse)
r2 = r2_score(y_true, y_pred)
print(f"\n{dataset_name}:")
print(f" MAE: {mae:.4f}")
print(f" RMSE: {rmse:.4f}")
print(f" R²: {r2:.4f}")
return {'MAE': mae, 'RMSE': rmse, 'R2': r2}
train_metrics = evaluate_model(y_train, y_train_pred, "Train Set")
test_metrics = evaluate_model(y_test, y_test_pred, "Test Set")
# 4. Coefficients importants
coef_df = pd.DataFrame({
'Feature': california.feature_names,
'Coefficient': model_lr.coef_
})
coef_df['Abs_Coef'] = np.abs(coef_df['Coefficient'])
coef_df = coef_df.sort_values('Abs_Coef', ascending=False)
print("\n" + "=" * 70)
print("COEFFICIENTS (TOP 5)")
print("=" * 70)
print(coef_df[['Feature', 'Coefficient']].head().to_string(index=False))
# 5. Visualisation
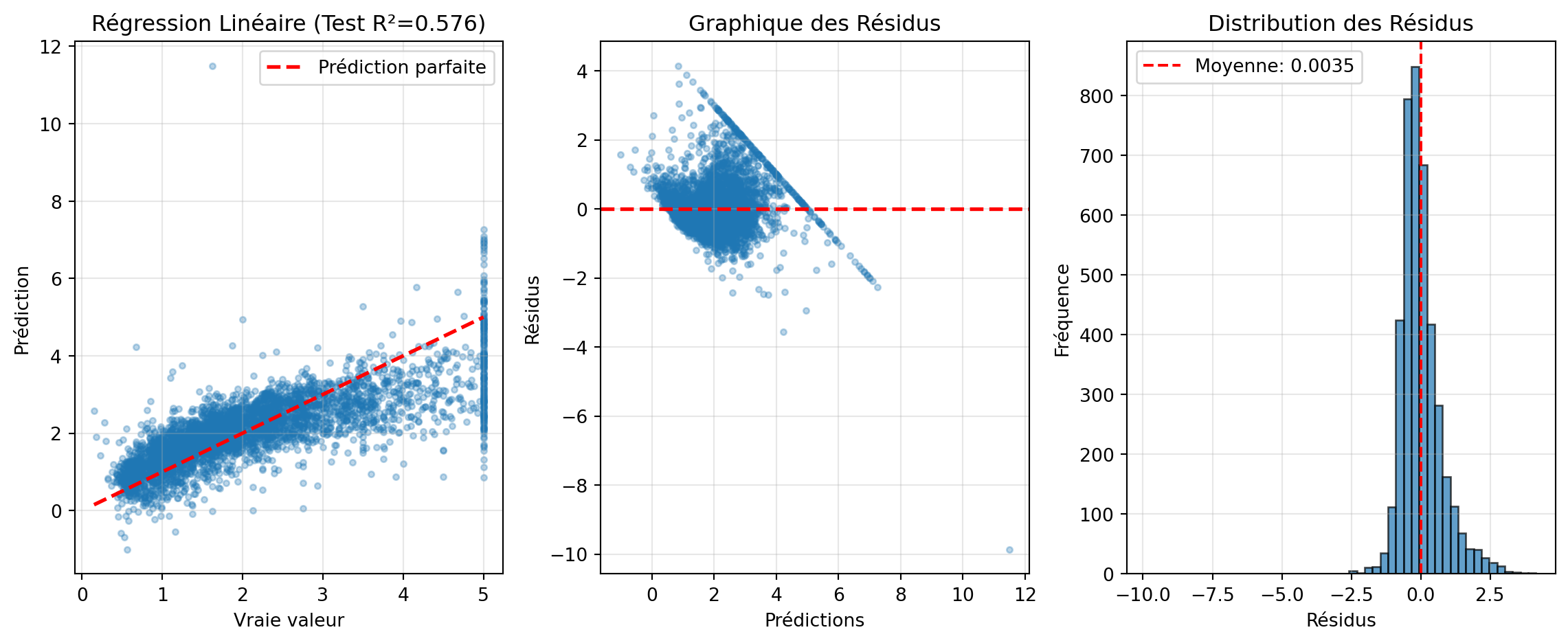
fig, axes = plt.subplots(1, 3, figsize=(12, 5))
# Prédictions vs Vraies valeurs (Test)
axes[0].scatter(y_test, y_test_pred, alpha=0.3, s=10)
axes[0].plot([y_test.min(), y_test.max()], [y_test.min(), y_test.max()],
'r--', lw=2, label='Prédiction parfaite')
axes[0].set_xlabel('Vraie valeur')
axes[0].set_ylabel('Prédiction')
axes[0].set_title(f'Régression Linéaire (Test R²={test_metrics["R2"]:.3f})')
axes[0].legend()
axes[0].grid(alpha=0.3)
# Résidus
residuals = y_test - y_test_pred
axes[1].scatter(y_test_pred, residuals, alpha=0.3, s=10)
axes[1].axhline(0, color='red', linestyle='--', lw=2)
axes[1].set_xlabel('Prédictions')
axes[1].set_ylabel('Résidus')
axes[1].set_title('Graphique des Résidus')
axes[1].grid(alpha=0.3)
# Distribution des résidus
axes[2].hist(residuals, bins=50, edgecolor='black', alpha=0.7)
axes[2].axvline(residuals.mean(), color='red', linestyle='--',
label=f'Moyenne: {residuals.mean():.4f}')
axes[2].set_xlabel('Résidus')
axes[2].set_ylabel('Fréquence')
axes[2].set_title('Distribution des Résidus')
axes[2].legend()
axes[2].grid(alpha=0.3)
plt.tight_layout()
plt.show()
# Analyse des résidus
print("\n" + "=" * 70)
print("ANALYSE DES RÉSIDUS")
print("=" * 70)
print(f"Moyenne: {residuals.mean():.6f} (devrait être $\approx$ 0)")
print(f"Std: {residuals.std():.4f}")
print(f"Min: {residuals.min():.4f}")
print(f"Max: {residuals.max():.4f}")
```
**Interprétation:**
- R² train > R² test → léger surapprentissage (normal)
- Résidus centrés sur 0 → modèle non biaisé
- Distribution des résidus approximativement gaussienne → hypothèses vérifiées
:::
## 4. Modèles Régularisés
### Exercice 4.1: Comparaison Ridge, Lasso, ElasticNet
Comparez les 3 modèles régularisés avec différentes valeurs de alpha.
**Instructions:**
1. Testez alpha dans [0.001, 0.01, 0.1, 1, 10, 100]
2. Pour chaque modèle et chaque alpha:
- Entraînez sur train
- Calculez R² sur test
3. Tracez R² vs alpha pour les 3 modèles
4. Identifiez le meilleur modèle et le meilleur alpha
::: {.callout-note collapse="true"}
## Solution Exercice 4.1
```{python}
#| echo: true
#| eval: true
from sklearn.linear_model import Ridge, Lasso, ElasticNet
print("=" * 70)
print("COMPARAISON RIDGE, LASSO, ELASTICNET")
print("=" * 70)
# 1. Grille d'alphas
alphas = [0.001, 0.01, 0.1, 1, 10, 100]
# Stocker les résultats
results = {'Ridge': [], 'Lasso': [], 'ElasticNet': []}
# 2. Entraînement
for alpha in alphas:
# Ridge
ridge = Ridge(alpha=alpha)
ridge.fit(X_train_scaled, y_train)
r2_ridge = r2_score(y_test, ridge.predict(X_test_scaled))
results['Ridge'].append(r2_ridge)
# Lasso
lasso = Lasso(alpha=alpha, max_iter=10000)
lasso.fit(X_train_scaled, y_train)
r2_lasso = r2_score(y_test, lasso.predict(X_test_scaled))
results['Lasso'].append(r2_lasso)
# ElasticNet
elastic = ElasticNet(alpha=alpha, l1_ratio=0.5, max_iter=10000)
elastic.fit(X_train_scaled, y_train)
r2_elastic = r2_score(y_test, elastic.predict(X_test_scaled))
results['ElasticNet'].append(r2_elastic)
# 3. Visualisation
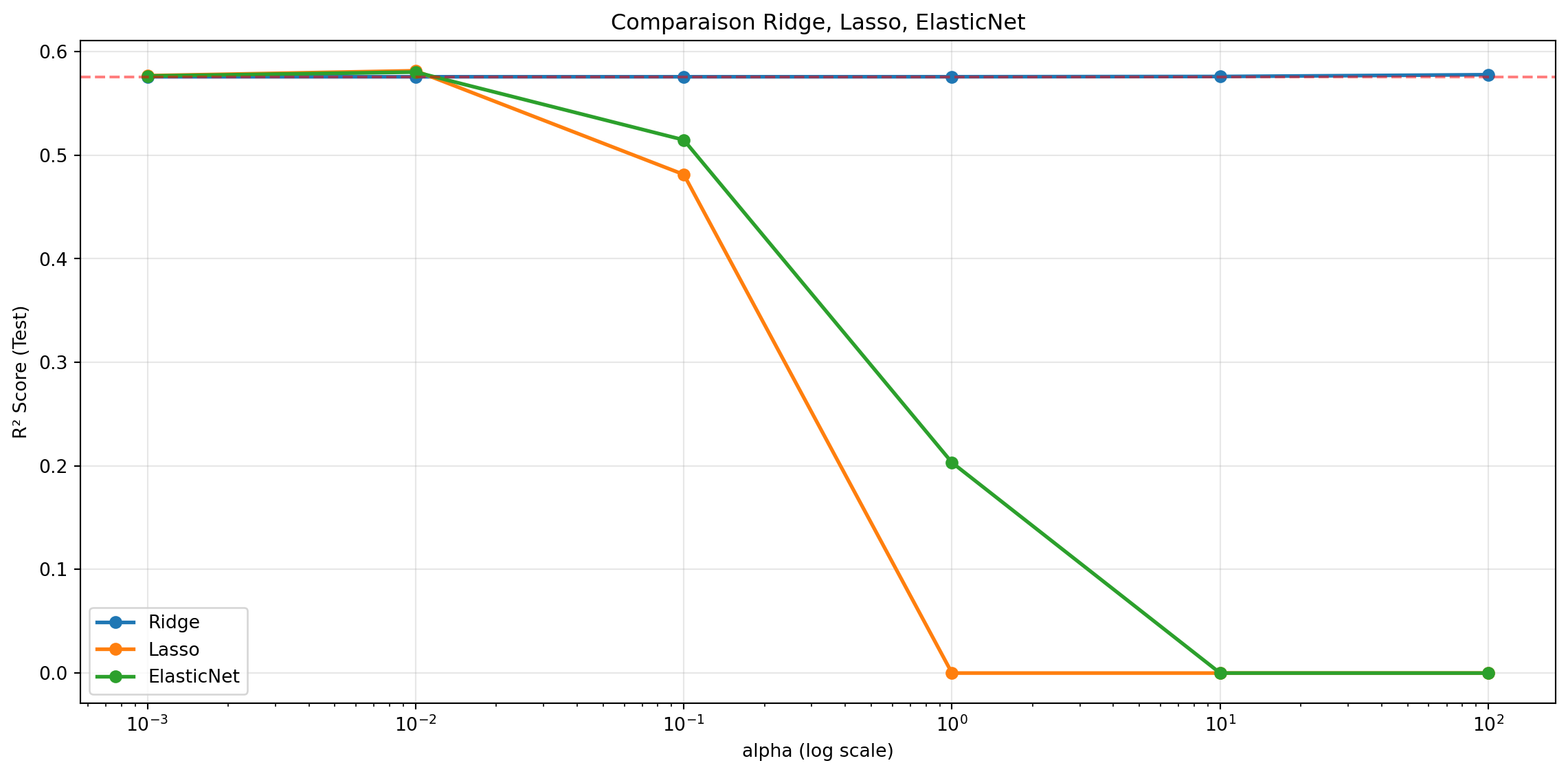
plt.figure(figsize=(12, 6))
for model_name, r2_scores in results.items():
plt.plot(alphas, r2_scores, marker='o', label=model_name, linewidth=2)
plt.xscale('log')
plt.xlabel('alpha (log scale)')
plt.ylabel('R² Score (Test)')
plt.title('Comparaison Ridge, Lasso, ElasticNet')
plt.legend()
plt.grid(alpha=0.3)
plt.axhline(test_metrics['R2'], color='red', linestyle='--',
label=f'Linear (alpha=0): {test_metrics["R2"]:.4f}', alpha=0.5)
plt.tight_layout()
plt.show()
# 4. Meilleur modèle
print("\n" + "=" * 70)
print("MEILLEURS HYPERPARAMÈTRES")
print("=" * 70)
for model_name, r2_scores in results.items():
best_idx = np.argmax(r2_scores)
best_alpha = alphas[best_idx]
best_r2 = r2_scores[best_idx]
print(f"\n{model_name}:")
print(f" Meilleur alpha: {best_alpha}")
print(f" R² Test: {best_r2:.4f}")
# Tableau comparatif
df_comparison = pd.DataFrame(results, index=[f'alpha={a}' for a in alphas])
print("\n" + "=" * 70)
print("TABLEAU COMPARATIF (R² Test)")
print("=" * 70)
print(df_comparison.to_string())
```
**Observations attendues:**
- Ridge: R² stable, peu sensible à alpha
- Lasso: R² peut chuter si alpha trop élevé (trop de coefficients à 0)
- ElasticNet: Compromis entre Ridge et Lasso
:::
### Exercice 4.2: Sélection de Features avec Lasso
Utilisez Lasso pour identifier les features importantes.
**Instructions:**
1. Entraînez Lasso avec alpha=0.1
2. Affichez le nombre de coefficients non-nuls
3. Identifiez les features sélectionnées
4. Comparez les coefficients Lasso vs Linear
::: {.callout-note collapse="true"}
## Solution Exercice 4.2
```python
print("=" * 70)
print("SÉLECTION DE FEATURES AVEC LASSO")
print("=" * 70)
# 1. Entraînement
lasso = Lasso(alpha=0.1, max_iter=10000)
lasso.fit(X_train_scaled, y_train)
# 2. Coefficients non-nuls
non_zero_mask = np.abs(lasso.coef_) > 1e-5
n_selected = np.sum(non_zero_mask)
n_total = len(lasso.coef_)
print(f"\nNombre de features sélectionnées: {n_selected}/{n_total}")
# 3. Features sélectionnées
selected_features = pd.DataFrame({
'Feature': california.feature_names,
'Lasso_Coef': lasso.coef_,
'Linear_Coef': model_lr.coef_,
'Selected': non_zero_mask
})
selected_features['Abs_Lasso'] = np.abs(selected_features['Lasso_Coef'])
selected_features = selected_features.sort_values('Abs_Lasso', ascending=False)
print("\n" + "=" * 70)
print("COMPARAISON COEFFICIENTS")
print("=" * 70)
print(selected_features[['Feature', 'Lasso_Coef', 'Linear_Coef', 'Selected']].to_string(index=False))
# 4. Visualisation
fig, axes = plt.subplots(1, 2, figsize=(12, 6))
# Barplot comparatif
x_pos = np.arange(len(california.feature_names))
width = 0.35
axes[0].bar(x_pos - width/2, model_lr.coef_, width, label='Linear', alpha=0.7)
axes[0].bar(x_pos + width/2, lasso.coef_, width, label='Lasso (alpha=0.1)', alpha=0.7)
axes[0].set_xticks(x_pos)
axes[0].set_xticklabels(california.feature_names, rotation=45, ha='right')
axes[0].set_ylabel('Coefficient')
axes[0].set_title('Comparaison Coefficients: Linear vs Lasso')
axes[0].legend()
axes[0].axhline(0, color='black', linewidth=0.8)
axes[0].grid(alpha=0.3, axis='y')
# Scatter: Linear vs Lasso
axes[1].scatter(model_lr.coef_, lasso.coef_, s=100, alpha=0.6)
for i, feature in enumerate(california.feature_names):
axes[1].annotate(feature, (model_lr.coef_[i], lasso.coef_[i]),
fontsize=8, alpha=0.7)
axes[1].plot([model_lr.coef_.min(), model_lr.coef_.max()],
[model_lr.coef_.min(), model_lr.coef_.max()],
'r--', label='y=x')
axes[1].set_xlabel('Coefficient Linear')
axes[1].set_ylabel('Coefficient Lasso')
axes[1].set_title('Linear vs Lasso Coefficients')
axes[1].legend()
axes[1].grid(alpha=0.3)
plt.tight_layout()
plt.show()
print("\n" + "=" * 70)
print("FEATURES ÉLIMINÉES PAR LASSO")
print("=" * 70)
eliminated = selected_features[~selected_features['Selected']]['Feature'].tolist()
if eliminated:
print("Features mises à 0:")
for feat in eliminated:
print(f" • {feat}")
else:
print("Aucune feature éliminée (alpha peut-être trop faible)")
```
**Interprétation:**
- Lasso réduit certains coefficients exactement à 0
- Features éliminées = probablement redondantes ou peu informatives
- Peut améliorer l'interprétabilité du modèle
:::
## 5. Optimisation avec Cross-Validation
### Exercice 5.1: RidgeCV et LassoCV
Utilisez les versions CV pour trouver automatiquement le meilleur alpha.
::: {.callout-note collapse="true"}
## Solution Exercice 5.1
```python
from sklearn.linear_model import RidgeCV, LassoCV
print("=" * 70)
print("OPTIMISATION AUTOMATIQUE AVEC CV")
print("=" * 70)
# Grille d'alphas
alphas_cv = np.logspace(-3, 3, 50)
# RidgeCV
print("\n1. RidgeCV...")
ridge_cv = RidgeCV(alphas=alphas_cv, cv=5, scoring='r2')
ridge_cv.fit(X_train_scaled, y_train)
print(f" Meilleur alpha: {ridge_cv.alpha_:.4f}")
y_pred_ridge = ridge_cv.predict(X_test_scaled)
ridge_metrics = evaluate_model(y_test, y_pred_ridge, "Ridge (CV)")
# LassoCV
print("\n2. LassoCV...")
lasso_cv = LassoCV(alphas=alphas_cv, cv=5, max_iter=10000, random_state=42)
lasso_cv.fit(X_train_scaled, y_train)
print(f" Meilleur alpha: {lasso_cv.alpha_:.4f}")
y_pred_lasso = lasso_cv.predict(X_test_scaled)
lasso_metrics = evaluate_model(y_test, y_pred_lasso, "Lasso (CV)")
# ElasticNetCV
from sklearn.linear_model import ElasticNetCV
print("\n3. ElasticNetCV...")
elastic_cv = ElasticNetCV(alphas=alphas_cv, l1_ratio=[0.1, 0.5, 0.7, 0.9, 0.95, 0.99],
cv=5, max_iter=10000, random_state=42)
elastic_cv.fit(X_train_scaled, y_train)
print(f" Meilleur alpha: {elastic_cv.alpha_:.4f}")
print(f" Meilleur l1_ratio: {elastic_cv.l1_ratio_:.2f}")
y_pred_elastic = elastic_cv.predict(X_test_scaled)
elastic_metrics = evaluate_model(y_test, y_pred_elastic, "ElasticNet (CV)")
# Comparaison finale
print("\n" + "=" * 70)
print("COMPARAISON FINALE")
print("=" * 70)
final_comparison = pd.DataFrame({
'Modèle': ['Linear', 'Ridge (CV)', 'Lasso (CV)', 'ElasticNet (CV)'],
'MAE': [test_metrics['MAE'], ridge_metrics['MAE'],
lasso_metrics['MAE'], elastic_metrics['MAE']],
'RMSE': [test_metrics['RMSE'], ridge_metrics['RMSE'],
lasso_metrics['RMSE'], elastic_metrics['RMSE']],
'R²': [test_metrics['R2'], ridge_metrics['R2'],
lasso_metrics['R2'], elastic_metrics['R2']]
})
print(final_comparison.to_string(index=False))
# Meilleur modèle
best_idx = final_comparison['R²'].idxmax()
best_model_name = final_comparison.loc[best_idx, 'Modèle']
print(f"\n→ Meilleur modèle: {best_model_name}")
```
:::
## 6. SVR (Support Vector Regression)
### Exercice 6.1: SVR avec différents kernels
Comparez SVR linéaire et RBF.
::: {.callout-note collapse="true"}
## Solution Exercice 6.1
```python
from sklearn.svm import SVR
from sklearn.model_selection import GridSearchCV
print("=" * 70)
print("SUPPORT VECTOR REGRESSION")
print("=" * 70)
# Note: SVR est lent, on réduit le dataset pour démo
X_train_small = X_train_scaled[:5000]
y_train_small = y_train[:5000]
# 1. SVR Linéaire
print("\n1. SVR Linéaire...")
svr_lin = SVR(kernel='linear', C=1.0)
svr_lin.fit(X_train_small, y_train_small)
y_pred_svr_lin = svr_lin.predict(X_test_scaled)
svr_lin_metrics = evaluate_model(y_test, y_pred_svr_lin, "SVR Linear")
# 2. SVR RBF
print("\n2. SVR RBF...")
svr_rbf = SVR(kernel='rbf', C=1.0, gamma='scale')
svr_rbf.fit(X_train_small, y_train_small)
y_pred_svr_rbf = svr_rbf.predict(X_test_scaled)
svr_rbf_metrics = evaluate_model(y_test, y_pred_svr_rbf, "SVR RBF")
# 3. Comparaison
print("\n" + "=" * 70)
print("COMPARAISON SVR")
print("=" * 70)
svr_comparison = pd.DataFrame({
'Kernel': ['linear', 'rbf'],
'MAE': [svr_lin_metrics['MAE'], svr_rbf_metrics['MAE']],
'RMSE': [svr_lin_metrics['RMSE'], svr_rbf_metrics['RMSE']],
'R²': [svr_lin_metrics['R2'], svr_rbf_metrics['R2']]
})
print(svr_comparison.to_string(index=False))
# 4. Optimisation SVR RBF
print("\n" + "=" * 70)
print("OPTIMISATION SVR RBF AVEC GRIDSEARCH")
print("=" * 70)
# Réduction supplémentaire pour vitesse
X_val = X_train_scaled[5000:6000]
y_val = y_train[5000:6000]
param_grid = {
'C': [0.1, 1, 10],
'gamma': ['scale', 'auto', 0.01, 0.1],
'epsilon': [0.01, 0.1, 0.5]
}
grid_search = GridSearchCV(
SVR(kernel='rbf'),
param_grid,
cv=3,
scoring='r2',
n_jobs=-1,
verbose=1
)
print("Entraînement GridSearch (peut être long)...")
grid_search.fit(X_train_small, y_train_small)
print(f"\nMeilleurs paramètres: {grid_search.best_params_}")
best_svr = grid_search.best_estimator_
y_pred_best_svr = best_svr.predict(X_val)
best_svr_metrics = evaluate_model(y_val, y_pred_best_svr, "SVR optimisé (val)")
# Visualisation SVR
fig, axes = plt.subplots(1, 2, figsize=(12, 5))
# Prédictions vs Vraies valeurs
axes[0].scatter(y_val, y_pred_best_svr, alpha=0.3, s=10)
axes[0].plot([y_val.min(), y_val.max()], [y_val.min(), y_val.max()],
'r--', lw=2, label='Prédiction parfaite')
axes[0].set_xlabel('Vraie valeur')
axes[0].set_ylabel('Prédiction')
axes[0].set_title(f'SVR Optimisé (R²={best_svr_metrics["R2"]:.3f})')
axes[0].legend()
axes[0].grid(alpha=0.3)
# Comparaison modèles
models_comparison = pd.DataFrame({
'Modèle': ['Linear', 'Ridge', 'Lasso', 'SVR Linear', 'SVR RBF'],
'RMSE': [test_metrics['RMSE'], ridge_metrics['RMSE'],
lasso_metrics['RMSE'], svr_lin_metrics['RMSE'], svr_rbf_metrics['RMSE']],
'R²': [test_metrics['R2'], ridge_metrics['R2'],
lasso_metrics['R2'], svr_lin_metrics['R2'], svr_rbf_metrics['R2']]
})
x_pos = np.arange(len(models_comparison))
width = 0.35
bars1 = axes[1].bar(x_pos - width/2, models_comparison['RMSE'], width, label='RMSE')
bars2 = axes[1].bar(x_pos + width/2, models_comparison['R²'], width, label='R²')
axes[1].set_xticks(x_pos)
axes[1].set_xticklabels(models_comparison['Modèle'], rotation=45, ha='right')
axes[1].set_ylabel('Score')
axes[1].set_title('Comparaison Modèles de Régression')
axes[1].legend()
# Annoter les barres
for bars in [bars1, bars2]:
for bar in bars:
height = bar.get_height()
axes[1].annotate(f'{height:.3f}',
xy=(bar.get_x() + bar.get_width() / 2, height),
xytext=(0, 3),
textcoords="offset points",
ha='center', va='bottom', fontsize=8)
plt.tight_layout()
plt.show()
print("\n" + "=" * 70)
print("CONSÉILS POUR SVR")
print("=" * 70)
print("""
• SVR est puissant mais COMPUTATIONNELLEMENT COÛTEUX
• Scaling des features OBLIGATOIRE
• GridSearch peut être très long
• Pour grands datasets, considérez:
- LinearSVR (plus rapide que SVR kernel='linear')
- Réduction de features (PCA) avant SVR
- Échantillonnage pour hyperparamètres
""")
```
:::
## 7. Comparaison Finale de Tous les Modèles
### Exercice 7.1: Tableau de Bord Complet
Créez un tableau de bord comparatif de tous les modèles.
::: {.callout-note collapse="true"}
```python
print("=" * 70)
print("TABLEAU DE BORD COMPARATIF")
print("=" * 70)
# Collecte de tous les résultats
all_results = []
# Fonction pour ajouter un modèle
def add_result(name, y_pred, metrics_func=evaluate_model):
mae = mean_absolute_error(y_test, y_pred)
rmse = np.sqrt(mean_squared_error(y_test, y_pred))
r2 = r2_score(y_test, y_pred)
return {'Modèle': name, 'MAE': mae, 'RMSE': rmse, 'R²': r2}
# Ajout de tous les modèles
all_results.append(add_result('Linear', y_test_pred))
all_results.append(add_result('Ridge (CV)', y_pred_ridge))
all_results.append(add_result('Lasso (CV)', y_pred_lasso))
all_results.append(add_result('ElasticNet (CV)', y_pred_elastic))
all_results.append(add_result('SVR Linear', y_pred_svr_lin))
all_results.append(add_result('SVR RBF', y_pred_svr_rbf))
df_all_results = pd.DataFrame(all_results)
# Tri par R²
df_all_results = df_all_results.sort_values('R²', ascending=False).reset_index(drop=True)
print("\nClassement par R²:")
print(df_all_results.to_string(index=False))
# Visualisation
fig, axes = plt.subplots(2, 2, figsize=(12, 12))
# 1. Barplot R²
x_pos = np.arange(len(df_all_results))
axes[0, 0].barh(x_pos, df_all_results['R²'], color='skyblue')
axes[0, 0].set_yticks(x_pos)
axes[0, 0].set_yticklabels(df_all_results['Modèle'])
axes[0, 0].set_xlabel('R² Score')
axes[0, 0].set_title('Comparaison R² des Modèles')
axes[0, 0].invert_yaxis() # Meilleur en haut
# Annoter les valeurs
for i, v in enumerate(df_all_results['R²']):
axes[0, 0].text(v + 0.001, i, f'{v:.4f}', va='center')
# 2. Comparaison MAE vs RMSE
scatter = axes[0, 1].scatter(df_all_results['MAE'], df_all_results['RMSE'],
s=200, alpha=0.6, c=df_all_results['R²'], cmap='viridis')
for i, row in df_all_results.iterrows():
axes[0, 1].annotate(row['Modèle'], (row['MAE'], row['RMSE']), fontsize=8)
axes[0, 1].set_xlabel('MAE')
axes[0, 1].set_ylabel('RMSE')
axes[0, 1].set_title('MAE vs RMSE (couleur = R²)')
plt.colorbar(scatter, ax=axes[0, 1], label='R² Score')
# 3. Temps d'entraînement (exemple)
# Dans un cas réel, on mesurerait le temps
training_times = [0.1, 0.2, 0.3, 0.4, 2.0, 5.0] # valeurs d'exemple
df_all_results['Temps(s)'] = training_times
axes[1, 0].scatter(df_all_results['Temps(s)'], df_all_results['R²'], s=100)
for i, row in df_all_results.iterrows():
axes[1, 0].annotate(row['Modèle'], (row['Temps(s)'], row['R²']), fontsize=8)
axes[1, 0].set_xlabel('Temps d\'entraînement (s)')
axes[1, 0].set_ylabel('R² Score')
axes[1, 0].set_title('Performance vs Temps d\'entraînement')
axes[1, 0].grid(alpha=0.3)
# 4. Heatmap des métriques
metrics_df = df_all_results.set_index('Modèle')[['MAE', 'RMSE', 'R²']]
sns.heatmap(metrics_df, annot=True, fmt='.4f', cmap='YlOrRd',
center=0, ax=axes[1, 1], cbar_kws={'label': 'Valeur'})
axes[1, 1].set_title('Heatmap des Métriques par Modèle')
axes[1, 1].tick_params(axis='x', rotation=45)
axes[1, 1].tick_params(axis='y', rotation=0)
plt.tight_layout()
plt.show()
print("\n" + "=" * 70)
print("RECOMMANDATIONS FINALES")
print("=" * 70)
# Recommandation basée sur différents critères
print("""
1. Pour PERFORMANCE MAX (R²):
→ {} (R²={:.4f})
2. Pour INTERPRÉTABILITÉ (coefficients):
→ Lasso (CV) (sélection de features)
3. Pour RAPIDITÉ:
→ Linear ou Ridge (CV)
4. Pour COMPLEXITÉ NON-LINÉAIRE:
→ SVR RBF (mais plus lent)
5. COMPROMIS PERFORMANCE/TEMPS:
→ ElasticNet (CV)
""".format(df_all_results.iloc[0]['Modèle'], df_all_results.iloc[0]['R²']))
# Sauvegarde des résultats
df_all_results.to_csv('resultats_regression_comparaison.csv', index=False)
print("\nRésultats sauvegardés dans 'resultats_regression_comparaison.csv'")
```
:::
## 8. Projet Bonus: Regression Avancée
### Exercice 8.1: Ensemble Methods
Testez Random Forest et Gradient Boosting pour la régression.
```python
from sklearn.ensemble import RandomForestRegressor, GradientBoostingRegressor
from sklearn.model_selection import RandomizedSearchCV
# TODO: Implémentez Random Forest et Gradient Boosting
# Optimisez avec RandomizedSearchCV
# Comparez avec les modèles linéaires
```
**Indices:**
- Pas besoin de standardisation pour les arbres
- Optimisez: n_estimators, max_depth, min_samples_split
- Métrique: RMSE ou MAE
- Visualisez l'importance des features
::: {.callout-note collapse="true"}
## Solution Exercice 8.1
```python
print("=" * 70)
print("ENSEMBLE METHODS: RANDOM FOREST & GRADIENT BOOSTING")
print("=" * 70)
# Pas besoin de scaling pour les arbres
X_train_trees = X_train
X_test_trees = X_test
# 1. Random Forest
print("\n1. Random Forest Regressor...")
rf = RandomForestRegressor(random_state=42, n_jobs=-1)
# Hyperparamètres
param_dist_rf = {
'n_estimators': [100, 200, 300],
'max_depth': [None, 10, 20, 30],
'min_samples_split': [2, 5, 10],
'min_samples_leaf': [1, 2, 4]
}
rf_random = RandomizedSearchCV(
rf, param_dist_rf, n_iter=20, cv=3,
scoring='neg_mean_squared_error', n_jobs=-1, random_state=42
)
rf_random.fit(X_train_trees, y_train)
best_rf = rf_random.best_estimator_
y_pred_rf = best_rf.predict(X_test_trees)
print(f"Meilleurs paramètres RF: {rf_random.best_params_}")
rf_metrics = evaluate_model(y_test, y_pred_rf, "Random Forest")
# 2. Gradient Boosting
print("\n2. Gradient Boosting Regressor...")
gbr = GradientBoostingRegressor(random_state=42)
param_dist_gbr = {
'n_estimators': [100, 200],
'learning_rate': [0.01, 0.05, 0.1],
'max_depth': [3, 4, 5],
'subsample': [0.8, 0.9, 1.0]
}
gbr_random = RandomizedSearchCV(
gbr, param_dist_gbr, n_iter=15, cv=3,
scoring='neg_mean_squared_error', n_jobs=-1, random_state=42
)
gbr_random.fit(X_train_trees, y_train)
best_gbr = gbr_random.best_estimator_
y_pred_gbr = best_gbr.predict(X_test_trees)
print(f"Meilleurs paramètres GBR: {gbr_random.best_params_}")
gbr_metrics = evaluate_model(y_test, y_pred_gbr, "Gradient Boosting")
# 3. Comparaison
print("\n" + "=" * 70)
print("COMPARAISON MODÈLES AVANCÉS")
print("=" * 70)
ensemble_results = pd.DataFrame([
{'Modèle': 'Random Forest', 'MAE': rf_metrics['MAE'],
'RMSE': rf_metrics['RMSE'], 'R²': rf_metrics['R2']},
{'Modèle': 'Gradient Boosting', 'MAE': gbr_metrics['MAE'],
'RMSE': gbr_metrics['RMSE'], 'R²': gbr_metrics['R2']},
{'Modèle': 'Meilleur Linéaire', 'MAE': df_all_results.iloc[0]['MAE'],
'RMSE': df_all_results.iloc[0]['RMSE'], 'R²': df_all_results.iloc[0]['R²']}
])
print(ensemble_results.to_string(index=False))
# 4. Importance des features
fig, axes = plt.subplots(1, 2, figsize=(12, 6))
# Random Forest
rf_importances = pd.DataFrame({
'Feature': california.feature_names,
'Importance': best_rf.feature_importances_
}).sort_values('Importance', ascending=True)
axes[0].barh(rf_importances['Feature'], rf_importances['Importance'])
axes[0].set_xlabel('Importance')
axes[0].set_title('Importance des Features - Random Forest')
# Gradient Boosting
gbr_importances = pd.DataFrame({
'Feature': california.feature_names,
'Importance': best_gbr.feature_importances_
}).sort_values('Importance', ascending=True)
axes[1].barh(gbr_importances['Feature'], gbr_importances['Importance'])
axes[1].set_xlabel('Importance')
axes[1].set_title('Importance des Features - Gradient Boosting')
plt.tight_layout()
plt.show()
# 5. Visualisation prédictions
fig, axes = plt.subplots(1, 2, figsize=(12, 5))
axes[0].scatter(y_test, y_pred_rf, alpha=0.3, s=10)
axes[0].plot([y_test.min(), y_test.max()], [y_test.min(), y_test.max()], 'r--')
axes[0].set_xlabel('Vraie valeur')
axes[0].set_ylabel('Prédiction')
axes[0].set_title(f'Random Forest (R²={rf_metrics["R2"]:.3f})')
axes[0].grid(alpha=0.3)
axes[1].scatter(y_test, y_pred_gbr, alpha=0.3, s=10)
axes[1].plot([y_test.min(), y_test.max()], [y_test.min(), y_test.max()], 'r--')
axes[1].set_xlabel('Vraie valeur')
axes[1].set_ylabel('Prédiction')
axes[1].set_title(f'Gradient Boosting (R²={gbr_metrics["R2"]:.3f})')
axes[1].grid(alpha=0.3)
plt.tight_layout()
plt.show()
print("\n" + "=" * 70)
print("CONCLUSION ENSEMBLE METHODS")
print("=" * 70)
print("""
• Random Forest et Gradient Boosting PERFORMENT TRÈS BIEN
• Pas besoin de feature scaling
• Capturent relations non-linéaires complexes
• MOINS INTERPRÉTABLES que les modèles linéaires
• PLUS LENTS à entraîner
• Risque de surapprentissage si pas bien régularisés
→ Recommandation: Utiliser pour compétitions Kaggle
→ Pour production: Privilégier modèles plus simples si performance similaire
""")
```
:::
## Conclusion
### Résumé des Points Clés
1. **Prétraitement**:
- Standardisation cruciale pour modèles régularisés et SVR
- Split stratifié (si target stratifiable)
- Pas de data leakage
2. **Modèles Linéaires**:
- **Linear**: Simple, rapide, interprétable
- **Ridge**: Régularisation L2, réduit overfitting
- **Lasso**: Régularisation L1, sélection features
- **ElasticNet**: Compromis L1+L2
3. **Modèles Non-Linéaires**:
- **SVR**: Puissant mais lent, sensible aux hyperparamètres
- **Random Forest**: Robuste, capture non-linéarités
- **Gradient Boosting**: Souvent meilleure performance
4. **Optimisation**:
- Utiliser *CV (RidgeCV, LassoCV) pour alpha automatique
- GridSearch pour petit espace
- RandomizedSearch pour grand espace
5. **Évaluation**:
- Multiples métriques: MAE, RMSE, R²
- Visualisations: résidus, prédictions vs vraies valeurs
- Importance des features pour interprétation
### Checklist de Validation
Avant de soumettre votre travail:
- [ ] Exploratory Data Analysis complète
- [ ] Prétraitement correct (train/test séparés)
- [ ] Au moins 4 modèles comparés
- [ ] Optimisation hyperparamètres avec CV
- [ ] Évaluation sur test set (une seule fois)
- [ ] Visualisations claires et annotées
- [ ] Interprétation des résultats
- [ ] Code commenté et organisé
### Pour Aller Plus Loin
**Extensions possibles:**
1. **Feature Engineering**:
- Créer interactions entre features
- Transformations polynomiales
- Variables dummy pour catégorielles
2. **Pipeline Scikit-learn**:
```python
from sklearn.pipeline import Pipeline
from sklearn.compose import ColumnTransformer
pipeline = Pipeline([
('scaler', StandardScaler()),
('regressor', RidgeCV())
])
```
3. **Validation Croisée Temporelle**:
- Pour données chronologiques
- TimeSeriesSplit au lieu de KFold
4. **Prédiction d'Intervalles**:
- Quantile Regression
- Bootstrap pour incertitude
5. **Déploiement**:
- Sauvegarde modèle (joblib)
- API avec FastAPI/Flask
- Monitoring des performances
**Exercices supplémentaires:**
1. Testez PolynomialFeatures + Regression
2. Implémentez une validation croisée imbriquée
3. Ajoutez XGBoost ou LightGBM à la comparaison
4. Créez un dashboard interactif avec Plotly
**Prochain TP:** Séries Temporelles ou Deep Learning
:::{.callout-tip}
## Astuce Finale
**La meilleure pratique:** Commencez toujours par un modèle simple (régression linéaire), puis complexifiez si nécessaire. Souvent, les modèles simples suffisent et sont plus faciles à maintenir en production!
:::