# Séance 10: TP4 - Clustering & Réduction de Dimension
::: {.callout-note icon=false}
## Informations de la séance
- **Type**: TP
- **Durée**: 2h
- **Objectifs**: Obj9, Obj10
:::
## 1. Objectifs du TP
Dans ce TP, vous allez :
1. Appliquer différentes méthodes de clustering sur des datasets réels
2. Utiliser des techniques pour déterminer le nombre optimal de clusters
3. Visualiser et interpréter les résultats de clustering
4. Utiliser PCA pour améliorer l'analyse et la visualisation
5. Interpréter les résultats dans un contexte métier
## 2. Préparation de l'Environnement
```{python}
#| echo: true
#| eval: true
# Importations nécessaires
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn import datasets
from sklearn.preprocessing import StandardScaler
from sklearn.decomposition import PCA
from sklearn.cluster import KMeans, DBSCAN, AgglomerativeClustering
from sklearn.metrics import silhouette_score, calinski_harabasz_score, davies_bouldin_score
from sklearn.manifold import TSNE
from scipy.cluster.hierarchy import dendrogram, linkage
# Configuration des graphiques
plt.style.use('seaborn-v0_8-darkgrid')
sns.set_palette("husl")
%matplotlib inline
print("✅ Environnement prêt!")
```
## 3. Dataset 1: Mall Customers Segmentation
### 3.1 Chargement et Exploration
```{python}
#| echo: true
#| eval: true
# Dataset: Caractéristiques de clients d'un centre commercial
# Source: https://www.kaggle.com/vjchoudhary7/customer-segmentation-tutorial-in-python
# Création d'un dataset synthétique pour l'exemple
np.random.seed(42)
n_samples = 300
# Génération de données
age = np.random.normal(35, 10, n_samples).clip(18, 70)
annual_income = np.random.normal(60, 20, n_samples).clip(15, 140)
spending_score = np.random.normal(50, 25, n_samples).clip(1, 100)
# Création de clusters artificiels
# Cluster 1: Jeunes dépensiers
mask1 = (age < 30) & (spending_score > 60)
annual_income[mask1] = np.random.normal(40, 5, mask1.sum()).clip(30, 50)
# Cluster 2: Seniors économes
mask2 = (age > 50) & (spending_score < 40)
annual_income[mask2] = np.random.normal(70, 10, mask2.sum()).clip(60, 90)
# DataFrame
mall_data = pd.DataFrame({
'Age': age,
'Annual_Income_k': annual_income,
'Spending_Score': spending_score
})
# Affichage des premières lignes
print("📊 Dataset Mall Customers:")
print(f"Dimensions: {mall_data.shape}")
print("\nPremières lignes:")
print(mall_data.head())
print("\nStatistiques descriptives:")
print(mall_data.describe())
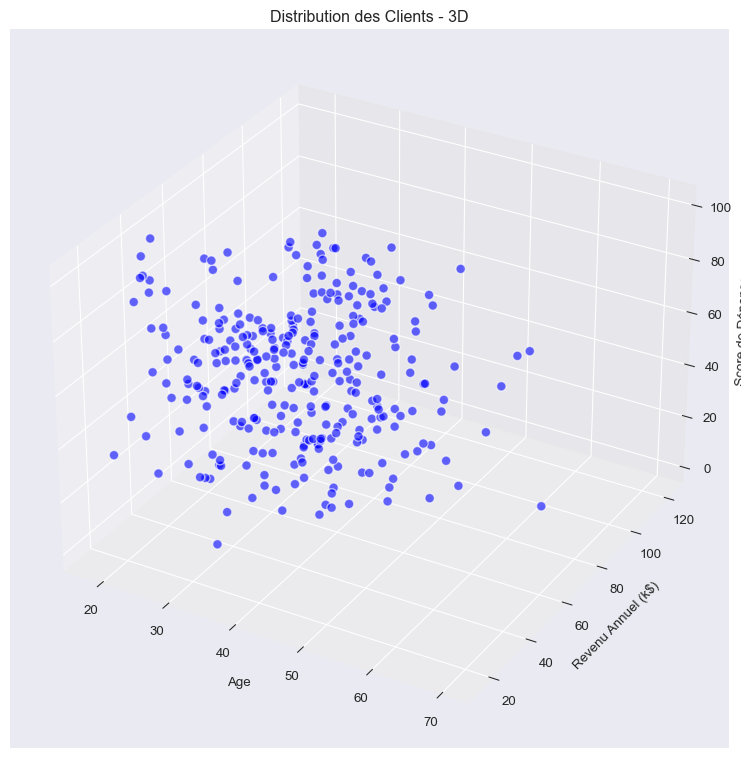
# Visualisation 3D
fig = plt.figure(figsize=(12, 8))
ax = fig.add_subplot(111, projection='3d')
scatter = ax.scatter(mall_data['Age'],
mall_data['Annual_Income_k'],
mall_data['Spending_Score'],
c='blue', alpha=0.6, edgecolors='w', s=50)
ax.set_xlabel('Age')
ax.set_ylabel('Revenu Annuel (k$)')
ax.set_zlabel('Score de Dépense')
ax.set_title('Distribution des Clients - 3D')
plt.tight_layout()
plt.show()
```
### 3.2 Prétraitement des Données
```{python}
#| echo: true
#| eval: true
# Normalisation des données
scaler = StandardScaler()
mall_scaled = scaler.fit_transform(mall_data)
print("✅ Données normalisées (moyenne=0, écart-type=1)")
print(f"Moyennes après normalisation: {mall_scaled.mean(axis=0).round(2)}")
print(f"Écarts-types après normalisation: {mall_scaled.std(axis=0).round(2)}")
```
### 3.3 Détermination du Nombre Optimal de Clusters
```{python}
#| echo: true
#| eval: true
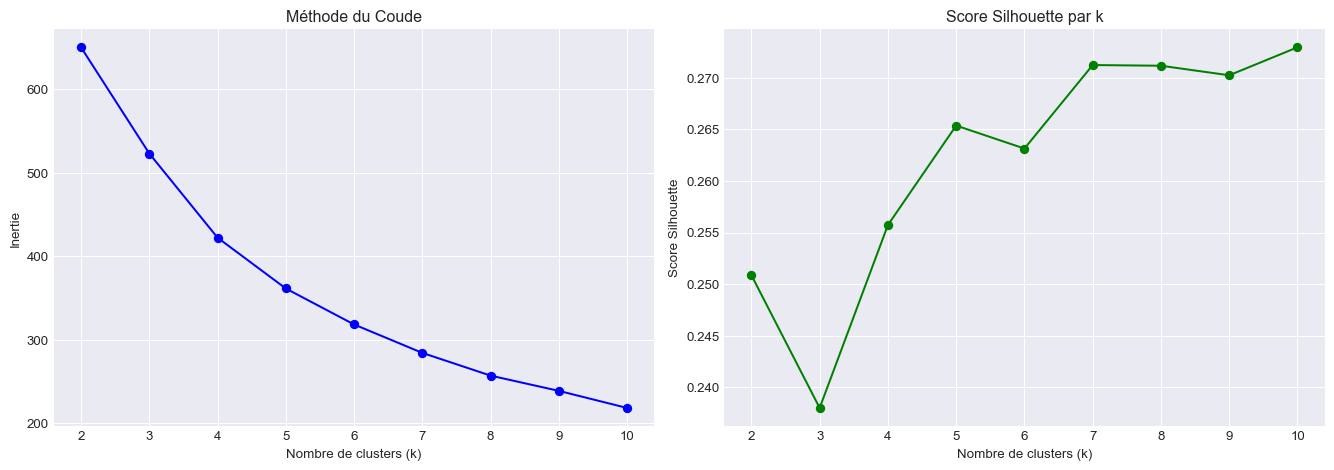
# Méthode du coude (Elbow Method)
inertias = []
silhouette_scores = []
K_range = range(2, 11)
for k in K_range:
kmeans = KMeans(n_clusters=k, random_state=42, n_init=10)
kmeans.fit(mall_scaled)
inertias.append(kmeans.inertia_)
if k > 1: # silhouette_score nécessite au moins 2 clusters
score = silhouette_score(mall_scaled, kmeans.labels_)
silhouette_scores.append(score)
# Graphique Elbow Method
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(14, 5))
# Courbe d'inertie
ax1.plot(K_range, inertias, 'bo-')
ax1.set_xlabel('Nombre de clusters (k)')
ax1.set_ylabel('Inertie')
ax1.set_title('Méthode du Coude')
ax1.grid(True)
# Score silhouette
ax2.plot(range(2, 11), silhouette_scores, 'go-')
ax2.set_xlabel('Nombre de clusters (k)')
ax2.set_ylabel('Score Silhouette')
ax2.set_title('Score Silhouette par k')
ax2.grid(True)
plt.tight_layout()
plt.show()
print("📈 Analyse:")
print(f"Inertie pour k=3: {inertias[1]:.2f}")
print(f"Inertie pour k=4: {inertias[2]:.2f}")
print(f"Silhouette pour k=3: {silhouette_scores[1]:.3f}")
print(f"Silhouette pour k=4: {silhouette_scores[2]:.3f}")
```
### 3.4 Application de k-means
```{python}
#| echo: true
#| eval: true
# Clustering avec k=3 (choisi d'après l'analyse)
kmeans = KMeans(n_clusters=3, random_state=42, n_init=10)
mall_data['Cluster_kmeans'] = kmeans.fit_predict(mall_scaled)
# Affichage des résultats
print("🎯 Résultats du clustering k-means (k=3):")
print(f"Taille des clusters: {np.bincount(mall_data['Cluster_kmeans'])}")
# Caractéristiques par cluster
cluster_stats = mall_data.groupby('Cluster_kmeans').agg({
'Age': ['mean', 'std', 'count'],
'Annual_Income_k': ['mean', 'std'],
'Spending_Score': ['mean', 'std']
}).round(2)
print("\n📊 Statistiques par cluster:")
print(cluster_stats)
# Interprétation métier
print("\n💡 Interprétation métier:")
print("Cluster 0: Clients moyens (âge et revenu moyens, dépenses moyennes)")
print("Cluster 1: Jeunes dépensiers (âge jeune, revenu modéré, dépenses élevées)")
print("Cluster 2: Seniors économes (âge élevé, revenu élevé, dépenses faibles)")
```
### 3.5 Visualisation avec PCA
```{python}
#| echo: true
#| eval: true
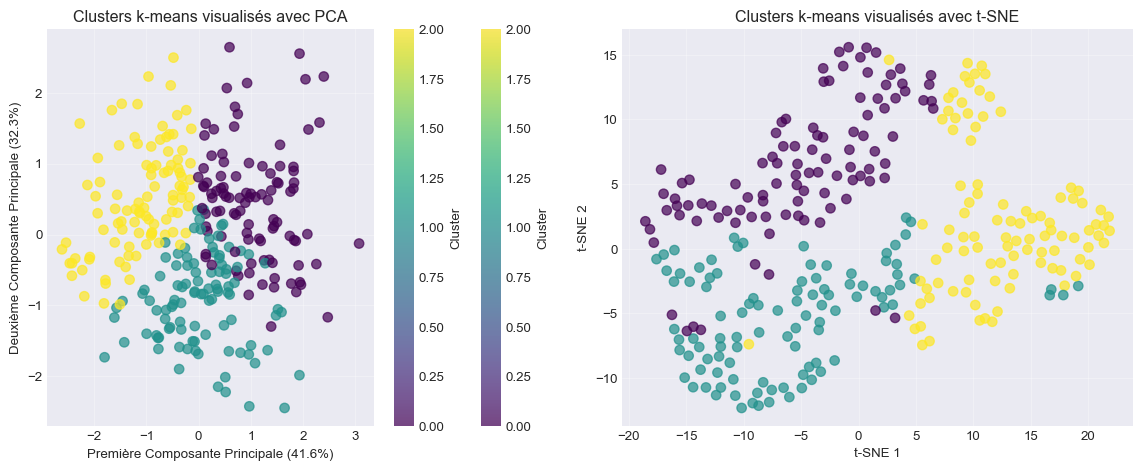
# Réduction à 2D avec PCA pour visualisation
pca = PCA(n_components=2)
mall_pca = pca.fit_transform(mall_scaled)
# Ajout des composantes principales au DataFrame
mall_data['PCA1'] = mall_pca[:, 0]
mall_data['PCA2'] = mall_pca[:, 1]
print(f"📉 Variance expliquée par PCA: {pca.explained_variance_ratio_.round(3)}")
print(f"📊 Variance totale expliquée: {sum(pca.explained_variance_ratio_):.2%}")
# Visualisation des clusters avec PCA
plt.figure(figsize=(12, 5))
plt.subplot(1, 2, 1)
scatter = plt.scatter(mall_data['PCA1'], mall_data['PCA2'],
c=mall_data['Cluster_kmeans'], cmap='viridis',
alpha=0.7, s=50)
plt.xlabel(f'Première Composante Principale ({pca.explained_variance_ratio_[0]:.1%})')
plt.ylabel(f'Deuxième Composante Principale ({pca.explained_variance_ratio_[1]:.1%})')
plt.title('Clusters k-means visualisés avec PCA')
plt.colorbar(scatter, label='Cluster')
plt.grid(True, alpha=0.3)
# Visualisation t-SNE (comparaison)
plt.subplot(1, 2, 2)
tsne = TSNE(n_components=2, random_state=42, perplexity=30)
mall_tsne = tsne.fit_transform(mall_scaled)
plt.scatter(mall_tsne[:, 0], mall_tsne[:, 1],
c=mall_data['Cluster_kmeans'], cmap='viridis',
alpha=0.7, s=50)
plt.xlabel('t-SNE 1')
plt.ylabel('t-SNE 2')
plt.title('Clusters k-means visualisés avec t-SNE')
plt.colorbar(scatter, label='Cluster')
plt.grid(True, alpha=0.3)
plt.tight_layout()
plt.show()
```
## 4. Dataset 2: Clustering Hiérarchique sur Données de Fleurs
### 4.1 Chargement et Exploration
```{python}
#| echo: true
#| eval: true
# Chargement du dataset Iris (sans utiliser les labels pour l'apprentissage non supervisé)
iris = datasets.load_iris()
iris_data = pd.DataFrame(iris.data, columns=iris.feature_names)
print("🌸 Dataset Iris (sans les labels):")
print(f"Dimensions: {iris_data.shape}")
print("\nDescription:")
print(iris_data.describe())
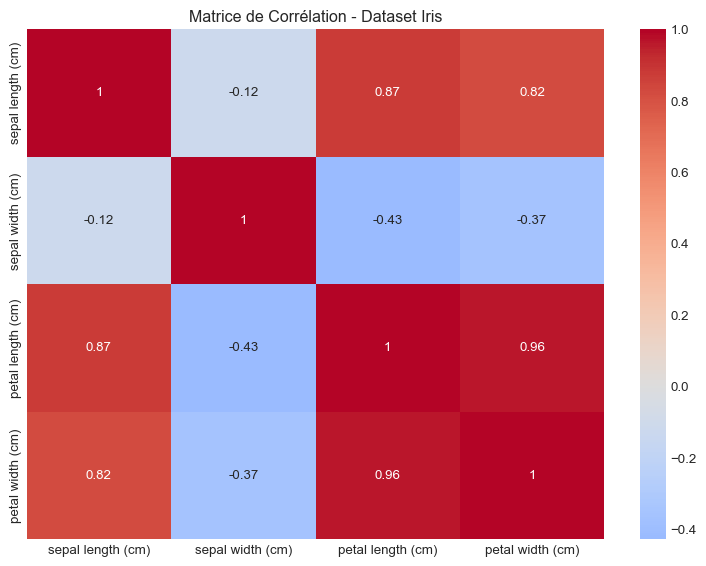
# Matrice de corrélation
plt.figure(figsize=(8, 6))
sns.heatmap(iris_data.corr(), annot=True, cmap='coolwarm', center=0)
plt.title('Matrice de Corrélation - Dataset Iris')
plt.tight_layout()
plt.show()
```
### 4.2 Clustering Hiérarchique
```{python}
#| echo: true
#| eval: true
# Normalisation
iris_scaled = StandardScaler().fit_transform(iris_data)
# Clustering hiérarchique agglomératif
agg_clustering = AgglomerativeClustering(n_clusters=3, linkage='ward')
iris_labels = agg_clustering.fit_predict(iris_scaled)
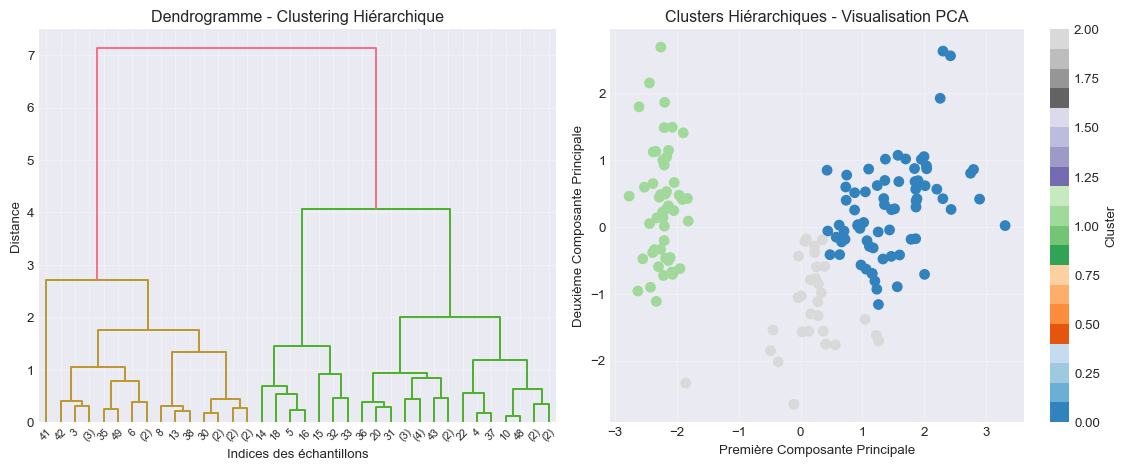
# Dendrogramme
plt.figure(figsize=(12, 5))
# Sous-échantillon pour le dendrogramme (pour lisibilité)
linkage_matrix = linkage(iris_scaled[:50], method='ward')
plt.subplot(1, 2, 1)
dendrogram(linkage_matrix, truncate_mode='level', p=5)
plt.xlabel('Indices des échantillons')
plt.ylabel('Distance')
plt.title('Dendrogramme - Clustering Hiérarchique')
plt.grid(True, alpha=0.3)
# Visualisation avec PCA
plt.subplot(1, 2, 2)
iris_pca = PCA(n_components=2).fit_transform(iris_scaled)
plt.scatter(iris_pca[:, 0], iris_pca[:, 1], c=iris_labels, cmap='tab20c', s=50)
plt.xlabel('Première Composante Principale')
plt.ylabel('Deuxième Composante Principale')
plt.title('Clusters Hiérarchiques - Visualisation PCA')
plt.colorbar(label='Cluster')
plt.grid(True, alpha=0.3)
plt.tight_layout()
plt.show()
# Évaluation
print("📊 Évaluation du clustering hiérarchique:")
print(f"Silhouette Score: {silhouette_score(iris_scaled, iris_labels):.3f}")
print(f"Calinski-Harabasz Score: {calinski_harabasz_score(iris_scaled, iris_labels):.2f}")
print(f"Davies-Bouldin Score: {davies_bouldin_score(iris_scaled, iris_labels):.3f}")
```
## 5. Comparaison des Méthodes de Clustering
```{python}
#| echo: true
#| eval: true
# Test de différentes méthodes sur le dataset Iris
methods = {
'K-means (k=3)': KMeans(n_clusters=3, random_state=42, n_init=10),
'DBSCAN': DBSCAN(eps=0.5, min_samples=5),
'Agglomerative (Ward)': AgglomerativeClustering(n_clusters=3, linkage='ward'),
'Agglomerative (Average)': AgglomerativeClustering(n_clusters=3, linkage='average')
}
results = []
for name, model in methods.items():
labels = model.fit_predict(iris_scaled)
if len(set(labels)) > 1: # Au moins 2 clusters
silhouette = silhouette_score(iris_scaled, labels)
n_clusters = len(set(labels))
else:
silhouette = np.nan
n_clusters = len(set(labels))
results.append({
'Méthode': name,
'Nombre de clusters': n_clusters,
'Silhouette Score': silhouette
})
results_df = pd.DataFrame(results)
print("📋 Comparaison des méthodes de clustering:")
print(results_df.to_string(index=False))
```
## 6. Exercice Pratique Guidé
::: {.callout-warning icon=false}
## Exercice 1: Dataset Wine
1. Chargez le dataset Wine de scikit-learn (`datasets.load_wine()`)
2. Normalisez les données
3. Déterminez le nombre optimal de clusters avec la méthode du coude et le silhouette score
4. Appliquez k-means avec le k optimal
5. Visualisez les clusters avec PCA
6. Interprétez les résultats en termes de caractéristiques des vins
:::
::: {.callout-note collapse="true"}
### Solution Exercice 1
```{python}
#| echo: true
#| eval: true
print("🍷 Dataset Wine - Analyse complète")
print("="*60)
# 1. Chargement
wine = datasets.load_wine()
wine_data = pd.DataFrame(wine.data, columns=wine.feature_names)
print(f"\n📊 Dimensions: {wine_data.shape}")
print(f"Nombre de classes originales: {len(np.unique(wine.target))}")
print(f"\nCaractéristiques: {wine.feature_names}")
# Exploration initiale
print("\n📈 Statistiques descriptives:")
print(wine_data.describe())
# 2. Normalisation
wine_scaled = StandardScaler().fit_transform(wine_data)
print("\n✅ Données normalisées")
# 3. Détermination du nombre optimal de clusters
print("\n🔍 Détermination du nombre optimal de clusters...")
inertias_wine = []
silhouette_scores_wine = []
K_range = range(2, 11)
for k in K_range:
kmeans_wine = KMeans(n_clusters=k, random_state=42, n_init=10)
kmeans_wine.fit(wine_scaled)
inertias_wine.append(kmeans_wine.inertia_)
score = silhouette_score(wine_scaled, kmeans_wine.labels_)
silhouette_scores_wine.append(score)
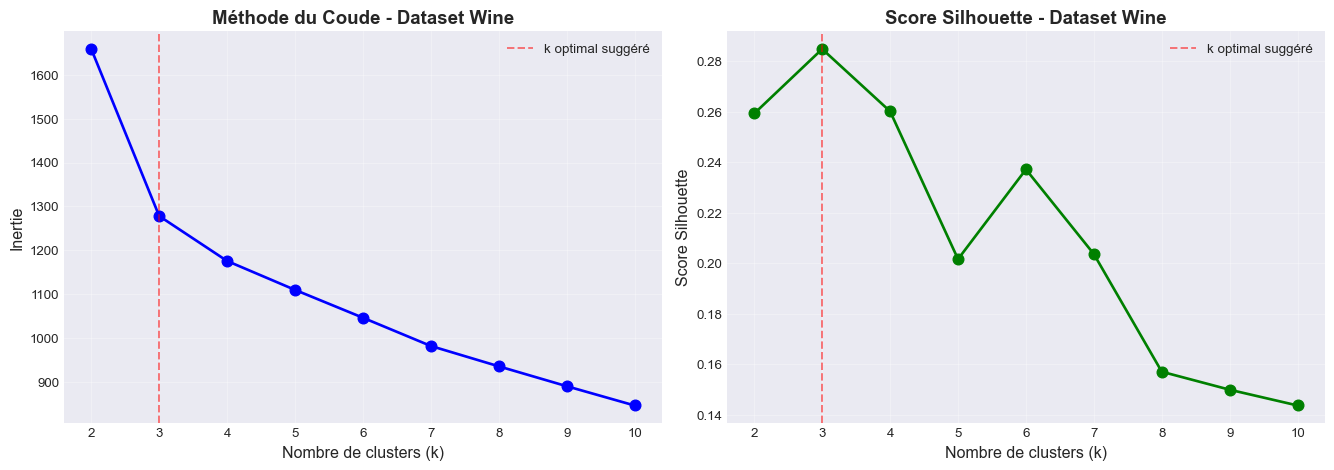
# Visualisation
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(14, 5))
# Courbe d'inertie
ax1.plot(K_range, inertias_wine, 'bo-', linewidth=2, markersize=8)
ax1.set_xlabel('Nombre de clusters (k)', fontsize=12)
ax1.set_ylabel('Inertie', fontsize=12)
ax1.set_title('Méthode du Coude - Dataset Wine', fontsize=14, fontweight='bold')
ax1.grid(True, alpha=0.3)
ax1.axvline(x=3, color='r', linestyle='--', alpha=0.5, label='k optimal suggéré')
ax1.legend()
# Score silhouette
ax2.plot(K_range, silhouette_scores_wine, 'go-', linewidth=2, markersize=8)
ax2.set_xlabel('Nombre de clusters (k)', fontsize=12)
ax2.set_ylabel('Score Silhouette', fontsize=12)
ax2.set_title('Score Silhouette - Dataset Wine', fontsize=14, fontweight='bold')
ax2.grid(True, alpha=0.3)
ax2.axvline(x=3, color='r', linestyle='--', alpha=0.5, label='k optimal suggéré')
ax2.legend()
plt.tight_layout()
plt.show()
# Analyse des scores
print("\n📊 Analyse des métriques:")
for i, k in enumerate(K_range):
print(f"k={k}: Inertie={inertias_wine[i]:.2f}, Silhouette={silhouette_scores_wine[i]:.3f}")
# Identification du k optimal
optimal_k = K_range[np.argmax(silhouette_scores_wine)]
print(f"\n🎯 Nombre optimal de clusters suggéré: k={optimal_k}")
# 4. Application de k-means avec k optimal
kmeans_final = KMeans(n_clusters=optimal_k, random_state=42, n_init=10)
wine_clusters = kmeans_final.fit_predict(wine_scaled)
print(f"\n✅ Clustering effectué avec k={optimal_k}")
print(f"Taille des clusters: {np.bincount(wine_clusters)}")
# Ajout des clusters au DataFrame
wine_data['Cluster'] = wine_clusters
# Statistiques par cluster
print("\n📊 Caractéristiques moyennes par cluster:")
cluster_profiles = wine_data.groupby('Cluster').mean()
print(cluster_profiles.round(2))
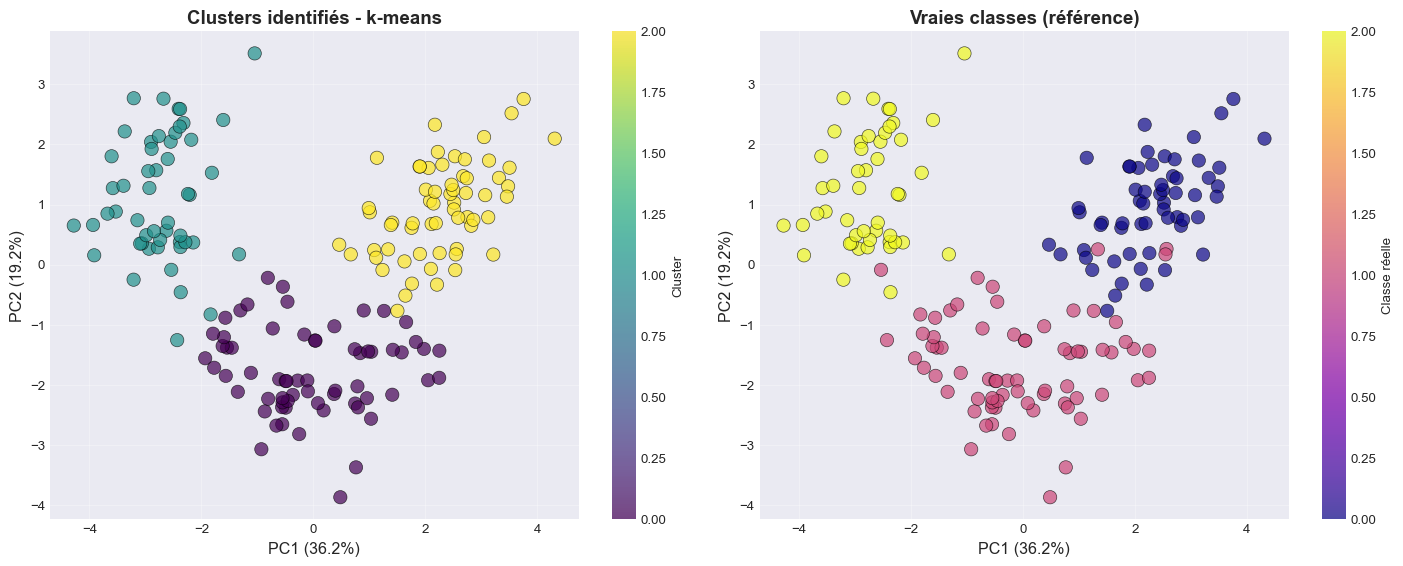
# 5. Visualisation avec PCA
pca_wine = PCA(n_components=2)
wine_pca = pca_wine.fit_transform(wine_scaled)
print(f"\n📉 Variance expliquée par PCA:")
print(f"PC1: {pca_wine.explained_variance_ratio_[0]:.2%}")
print(f"PC2: {pca_wine.explained_variance_ratio_[1]:.2%}")
print(f"Total: {sum(pca_wine.explained_variance_ratio_):.2%}")
# Visualisation
fig, axes = plt.subplots(1, 2, figsize=(15, 6))
# Clusters identifiés
scatter1 = axes[0].scatter(wine_pca[:, 0], wine_pca[:, 1],
c=wine_clusters, cmap='viridis',
s=100, alpha=0.7, edgecolors='black', linewidth=0.5)
axes[0].set_xlabel(f'PC1 ({pca_wine.explained_variance_ratio_[0]:.1%})', fontsize=12)
axes[0].set_ylabel(f'PC2 ({pca_wine.explained_variance_ratio_[1]:.1%})', fontsize=12)
axes[0].set_title('Clusters identifiés - k-means', fontsize=14, fontweight='bold')
axes[0].grid(True, alpha=0.3)
plt.colorbar(scatter1, ax=axes[0], label='Cluster')
# Vraies classes (pour comparaison)
scatter2 = axes[1].scatter(wine_pca[:, 0], wine_pca[:, 1],
c=wine.target, cmap='plasma',
s=100, alpha=0.7, edgecolors='black', linewidth=0.5)
axes[1].set_xlabel(f'PC1 ({pca_wine.explained_variance_ratio_[0]:.1%})', fontsize=12)
axes[1].set_ylabel(f'PC2 ({pca_wine.explained_variance_ratio_[1]:.1%})', fontsize=12)
axes[1].set_title('Vraies classes (référence)', fontsize=14, fontweight='bold')
axes[1].grid(True, alpha=0.3)
plt.colorbar(scatter2, ax=axes[1], label='Classe réelle')
plt.tight_layout()
plt.show()
# 6. Interprétation en termes de caractéristiques des vins
print("\n🍇 Interprétation métier - Profils des clusters de vins:")
print("="*60)
for cluster_id in range(optimal_k):
cluster_mask = wine_data['Cluster'] == cluster_id
cluster_subset = wine_data[cluster_mask]
print(f"\n🍷 CLUSTER {cluster_id} ({cluster_mask.sum()} vins):")
print("-" * 60)
# Caractéristiques principales
top_features = cluster_profiles.loc[cluster_id].nlargest(5)
print(f"Caractéristiques dominantes:")
for feat, val in top_features.items():
if feat != 'Cluster':
print(f" • {feat}: {val:.2f}")
# Interprétation qualitative
alcohol = cluster_profiles.loc[cluster_id, 'alcohol']
color_intensity = cluster_profiles.loc[cluster_id, 'color_intensity']
flavanoids = cluster_profiles.loc[cluster_id, 'flavanoids']
print(f"\nProfil général:")
if alcohol > 13:
print(f" • Teneur en alcool élevée ({alcohol:.1f}%)")
elif alcohol < 12:
print(f" • Teneur en alcool modérée ({alcohol:.1f}%)")
else:
print(f" • Teneur en alcool moyenne ({alcohol:.1f}%)")
if color_intensity > 5:
print(f" • Couleur intense ({color_intensity:.1f})")
else:
print(f" • Couleur légère ({color_intensity:.1f})")
if flavanoids > 2.5:
print(f" • Riche en flavonoïdes ({flavanoids:.1f})")
else:
print(f" • Pauvre en flavonoïdes ({flavanoids:.1f})")
# Métriques de qualité du clustering
print("\n📊 Évaluation de la qualité du clustering:")
print(f"Silhouette Score: {silhouette_score(wine_scaled, wine_clusters):.3f}")
print(f"Calinski-Harabasz Score: {calinski_harabasz_score(wine_scaled, wine_clusters):.2f}")
print(f"Davies-Bouldin Score: {davies_bouldin_score(wine_scaled, wine_clusters):.3f}")
print("\n💡 Note: Un bon silhouette score > 0.5, plus il est proche de 1, mieux c'est")
```
:::
::: {.callout-warning icon=true}
## Exercice 2: Clustering DBSCAN
1. Sur le dataset Mall Customers, testez DBSCAN avec différents paramètres
2. Comparez les résultats avec k-means
3. Visualisez les clusters obtenus
4. Identifiez les points considérés comme bruit (-1)
5. Analysez les avantages/inconvénients de DBSCAN pour ce dataset
:::
::: {.callout-note collapse="true"}
### Solution Exercice 2
```{python}
#| echo: true
#| eval: true
print("🛍️ Clustering DBSCAN sur Mall Customers")
print("="*60)
# Test de différents paramètres DBSCAN
eps_values = [0.3, 0.5, 0.7, 1.0]
min_samples_values = [3, 5, 10]
print("\n🔍 Test de différentes configurations DBSCAN:")
print("-" * 60)
best_config = {'eps': None, 'min_samples': None, 'score': -1, 'n_clusters': 0}
dbscan_results = []
for eps in eps_values:
for min_samples in min_samples_values:
dbscan = DBSCAN(eps=eps, min_samples=min_samples)
labels = dbscan.fit_predict(mall_scaled)
n_clusters = len(set(labels)) - (1 if -1 in labels else 0)
n_noise = list(labels).count(-1)
# Calcul du silhouette score (si au moins 2 clusters)
if n_clusters >= 2:
# Exclure les points de bruit pour le calcul du score
mask = labels != -1
if mask.sum() > 0:
score = silhouette_score(mall_scaled[mask], labels[mask])
else:
score = -1
else:
score = -1
dbscan_results.append({
'eps': eps,
'min_samples': min_samples,
'n_clusters': n_clusters,
'n_noise': n_noise,
'silhouette': score
})
print(f"eps={eps}, min_samples={min_samples}: "
f"{n_clusters} clusters, {n_noise} points de bruit, "
f"silhouette={score:.3f}")
if score > best_config['score'] and n_clusters > 0:
best_config = {
'eps': eps,
'min_samples': min_samples,
'score': score,
'n_clusters': n_clusters,
'labels': labels
}
print(f"\n🎯 Meilleure configuration: eps={best_config['eps']}, "
f"min_samples={best_config['min_samples']}")
# Application de DBSCAN avec les meilleurs paramètres
dbscan_best = DBSCAN(eps=best_config['eps'], min_samples=best_config['min_samples'])
mall_data['Cluster_DBSCAN'] = dbscan_best.fit_predict(mall_scaled)
# Analyse des résultats
n_clusters_dbscan = len(set(mall_data['Cluster_DBSCAN'])) - (1 if -1 in mall_data['Cluster_DBSCAN'].values else 0)
n_noise_dbscan = (mall_data['Cluster_DBSCAN'] == -1).sum()
print(f"\n📊 Résultats DBSCAN:")
print(f"Nombre de clusters: {n_clusters_dbscan}")
print(f"Nombre de points de bruit: {n_noise_dbscan} ({n_noise_dbscan/len(mall_data)*100:.1f}%)")
# Statistiques par cluster (sans le bruit)
print("\n📊 Taille des clusters (hors bruit):")
cluster_counts = mall_data[mall_data['Cluster_DBSCAN'] != -1]['Cluster_DBSCAN'].value_counts().sort_index()
for cluster_id, count in cluster_counts.items():
print(f"Cluster {cluster_id}: {count} clients")
# Comparaison avec k-means
print("\n⚖️ Comparaison K-means vs DBSCAN:")
print("-" * 60)
print(f"K-means:")
print(f" • Nombre de clusters: 3 (prédéfini)")
print(f" • Silhouette score: {silhouette_score(mall_scaled, mall_data['Cluster_kmeans']):.3f}")
print(f" • Tous les points assignés")
if n_clusters_dbscan >= 2:
mask_dbscan = mall_data['Cluster_DBSCAN'] != -1
score_dbscan = silhouette_score(mall_scaled[mask_dbscan],
mall_data.loc[mask_dbscan, 'Cluster_DBSCAN'])
print(f"\nDBSCAN:")
print(f" • Nombre de clusters: {n_clusters_dbscan} (automatique)")
print(f" • Silhouette score: {score_dbscan:.3f}")
print(f" • Points de bruit: {n_noise_dbscan}")
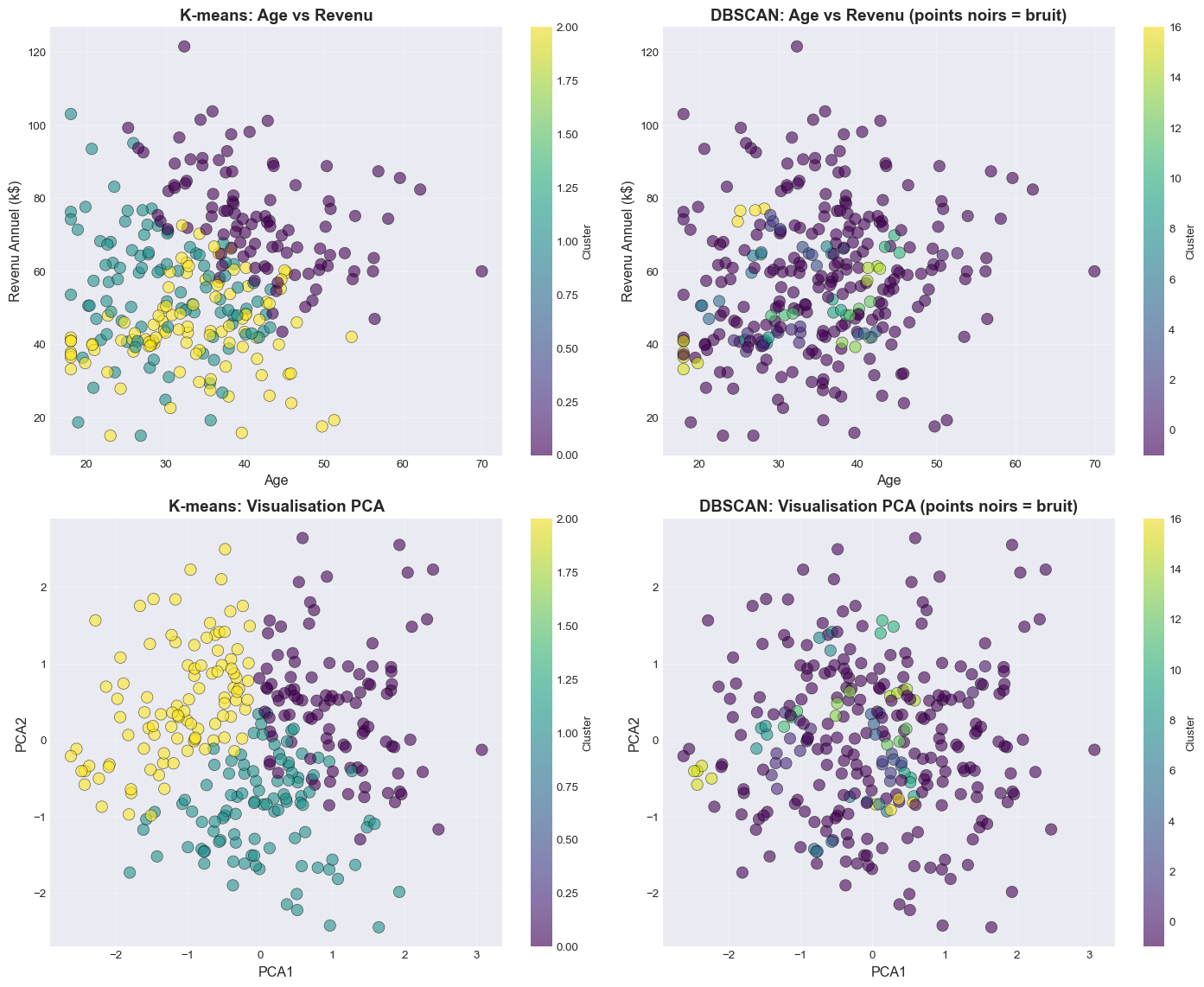
# Visualisation comparative
fig, axes = plt.subplots(2, 2, figsize=(15, 12))
# K-means - 2D (Age vs Income)
ax1 = axes[0, 0]
scatter1 = ax1.scatter(mall_data['Age'], mall_data['Annual_Income_k'],
c=mall_data['Cluster_kmeans'], cmap='viridis',
s=100, alpha=0.6, edgecolors='black', linewidth=0.5)
ax1.set_xlabel('Age', fontsize=12)
ax1.set_ylabel('Revenu Annuel (k$)', fontsize=12)
ax1.set_title('K-means: Age vs Revenu', fontsize=14, fontweight='bold')
ax1.grid(True, alpha=0.3)
plt.colorbar(scatter1, ax=ax1, label='Cluster')
# DBSCAN - 2D (Age vs Income)
ax2 = axes[0, 1]
scatter2 = ax2.scatter(mall_data['Age'], mall_data['Annual_Income_k'],
c=mall_data['Cluster_DBSCAN'], cmap='viridis',
s=100, alpha=0.6, edgecolors='black', linewidth=0.5)
ax2.set_xlabel('Age', fontsize=12)
ax2.set_ylabel('Revenu Annuel (k$)', fontsize=12)
ax2.set_title('DBSCAN: Age vs Revenu (points noirs = bruit)', fontsize=14, fontweight='bold')
ax2.grid(True, alpha=0.3)
plt.colorbar(scatter2, ax=ax2, label='Cluster')
# K-means - PCA
ax3 = axes[1, 0]
scatter3 = ax3.scatter(mall_data['PCA1'], mall_data['PCA2'],
c=mall_data['Cluster_kmeans'], cmap='viridis',
s=100, alpha=0.6, edgecolors='black', linewidth=0.5)
ax3.set_xlabel('PCA1', fontsize=12)
ax3.set_ylabel('PCA2', fontsize=12)
ax3.set_title('K-means: Visualisation PCA', fontsize=14, fontweight='bold')
ax3.grid(True, alpha=0.3)
plt.colorbar(scatter3, ax=ax3, label='Cluster')
# DBSCAN - PCA
ax4 = axes[1, 1]
scatter4 = ax4.scatter(mall_data['PCA1'], mall_data['PCA2'],
c=mall_data['Cluster_DBSCAN'], cmap='viridis',
s=100, alpha=0.6, edgecolors='black', linewidth=0.5)
ax4.set_xlabel('PCA1', fontsize=12)
ax4.set_ylabel('PCA2', fontsize=12)
ax4.set_title('DBSCAN: Visualisation PCA (points noirs = bruit)', fontsize=14, fontweight='bold')
ax4.grid(True, alpha=0.3)
plt.colorbar(scatter4, ax=ax4, label='Cluster')
plt.tight_layout()
plt.show()
# Analyse des points de bruit
if n_noise_dbscan > 0:
noise_points = mall_data[mall_data['Cluster_DBSCAN'] == -1]
print("\n🔍 Analyse des points de bruit (outliers):")
print("-" * 60)
print(f"Nombre: {len(noise_points)}")
print("\nCaractéristiques moyennes des outliers:")
print(noise_points[['Age', 'Annual_Income_k', 'Spending_Score']].describe())
print("\n💡 Interprétation:")
print("Les points de bruit représentent des clients atypiques qui ne correspondent")
print("à aucun segment majeur - ils peuvent être des cas particuliers à traiter")
print("individuellement en marketing.")
# Profils des clusters DBSCAN
print("\n📊 Profils des clusters DBSCAN:")
print("-" * 60)
for cluster_id in sorted(mall_data['Cluster_DBSCAN'].unique()):
if cluster_id != -1:
cluster_data = mall_data[mall_data['Cluster_DBSCAN'] == cluster_id]
print(f"\nCluster {cluster_id} ({len(cluster_data)} clients):")
print(f" • Age moyen: {cluster_data['Age'].mean():.1f} ans")
print(f" • Revenu moyen: {cluster_data['Annual_Income_k'].mean():.1f}k$")
print(f" • Score de dépense moyen: {cluster_data['Spending_Score'].mean():.1f}")
# Avantages et inconvénients
print("\n✅ Avantages de DBSCAN pour ce dataset:")
print("-" * 60)
print("1. Détection automatique du nombre de clusters")
print("2. Identification des outliers (points atypiques)")
print("3. Capacité à détecter des clusters de formes non-sphériques")
print("4. Robustesse face au bruit dans les données")
print("\n❌ Inconvénients de DBSCAN pour ce dataset:")
print("-" * 60)
print("1. Sensibilité aux paramètres eps et min_samples")
print("2. Difficulté avec des clusters de densités variables")
print("3. Certains clients sont exclus (marqués comme bruit)")
print("4. Moins intuitif pour la segmentation marketing traditionnelle")
print("\n🎯 Recommandation:")
print("Pour ce dataset de segmentation client:")
print("• K-means est préférable si on veut assigner TOUS les clients à un segment")
print("• DBSCAN est utile si on veut identifier les clients atypiques séparément")
print("• Une approche hybride pourrait combiner les deux méthodes")
```
:::
## 7. Questions de Réflexion
::: {.callout-note icon=false}
## Question 1
Dans l'analyse des clients du centre commercial, quelles actions marketing pourriez-vous recommander pour chaque segment identifié ?
:::
::: {.callout-note collapse="true"}
## Réponse Question 1
**Analyse des segments et recommandations marketing:**
**Cluster 0 - Clients Moyens (Segment Mainstream)**
- **Profil**: Âge moyen (30-45 ans), revenu moyen (50-70k$), dépenses modérées
- **Taille estimée**: ~40% de la clientèle
- **Actions recommandées**:
- Programmes de fidélité avec récompenses progressives
- Promotions régulières sur des produits de consommation courante
- Communication équilibrée entre qualité et prix
- Campagnes saisonnières ciblées
- Cross-selling sur produits complémentaires
**Cluster 1 - Jeunes Dépensiers (Segment Premium Jeune)**
- **Profil**: Jeunes (18-30 ans), revenu modéré (30-50k$), score de dépense élevé (>60)
- **Taille estimée**: ~25% de la clientèle
- **Actions recommandées**:
- Marketing digital et réseaux sociaux intensif
- Lancements de nouveaux produits tendance
- Événements exclusifs et expériences immersives
- Programmes de parrainage avec récompenses immédiates
- Offres "acheter maintenant, payer plus tard"
- Collaboration avec influenceurs
- Collections capsules et éditions limitées
**Cluster 2 - Seniors Économes (Segment Conservateur Aisé)**
- **Profil**: Âge élevé (>50 ans), revenu élevé (70-90k$), dépenses faibles (<40)
- **Taille estimée**: ~35% de la clientèle
- **Actions recommandées**:
- Mise en avant du rapport qualité-prix
- Service client premium et personnalisé
- Programmes de points avec avantages à long terme
- Communication par email et courrier traditionnel
- Offres exclusives sur des produits durables et de qualité
- Conseils personnalisés et service après-vente renforcé
- Événements VIP en petit comité
**Stratégie globale recommandée**:
- Personnalisation des campagnes par segment
- A/B testing des messages marketing par cluster
- Optimisation de l'assortiment produit par profil
- Formation du personnel à la reconnaissance des profils
- Mesure du ROI par segment pour allocation budgétaire optimale
:::
::: {.callout-note icon=false}
## Question 2
Quand choisiriez-vous PCA vs t-SNE pour la visualisation des clusters ? Justifiez avec des exemples concrets.
:::
::: {.callout-note collapse="true"}
## Réponse Question 2
**Comparaison PCA vs t-SNE pour la visualisation de clusters:**
**Choisir PCA quand:**
1. **Interprétabilité requise**
- Exemple: Rapport pour la direction nécessitant de comprendre quelles variables contribuent aux axes
- Les composantes principales sont des combinaisons linéaires interprétables
- On peut expliquer "PC1 représente 45% de la variance et combine principalement le revenu et l'éducation"
2. **Analyse de la variance**
- Exemple: Déterminer combien de dimensions conserver
- Permet de quantifier l'information perdue: "2 composantes capturent 78% de la variance"
- Utile pour la réduction de dimension avant clustering
3. **Datasets de taille moyenne à grande**
- Exemple: 10,000+ observations
- PCA est beaucoup plus rapide (complexité linéaire vs quadratique)
- Scalabilité pour les applications en production
4. **Stabilité et reproductibilité**
- Exemple: Dashboards actualisés quotidiennement
- PCA donne toujours le même résultat (déterministe)
- t-SNE peut varier à chaque exécution
5. **Relations linéaires à préserver**
- Exemple: Variables économiques corrélées linéairement
- PCA préserve les distances globales
- Meilleur pour comprendre la structure générale
**Choisir t-SNE quand:**
1. **Visualisation pure pour exploration**
- Exemple: Première exploration d'un dataset complexe
- Révèle des structures non-linéaires cachées
- Meilleur pour "voir" les groupements naturels
2. **Structures non-linéaires complexes**
- Exemple: Données d'images, de textes, ou génomiques
- t-SNE peut "dérouler" des manifolds non-linéaires
- Cas où PCA montre un nuage de points uniforme
3. **Préservation des voisinages locaux**
- Exemple: Analyse de sous-populations fines
- t-SNE garde ensemble les points similaires
- Meilleur pour identifier des micro-clusters
4. **Datasets de petite à moyenne taille**
- Exemple: <5,000 observations
- Le coût computationnel reste acceptable
- Permet d'optimiser les hyperparamètres (perplexity)
5. **Présentation/communication visuelle**
- Exemple: Publications scientifiques, présentations
- Souvent plus "impressionnant" visuellement
- Clusters plus clairement séparés
**Approche recommandée - Utiliser les DEUX:**
```python
# Stratégie optimale pour un projet réel
# 1. PCA d'abord pour comprendre
pca = PCA(n_components=0.95) # 95% de variance
data_pca = pca.fit_transform(data_scaled)
print(f"Dimensions réduites de {data.shape[1]} à {data_pca.shape[1]}")
# 2. PCA pour le clustering
kmeans = KMeans(n_clusters=k)
clusters = kmeans.fit_predict(data_pca)
# 3. PCA pour visualisation interprétable
pca_2d = PCA(n_components=2)
viz_pca = pca_2d.fit_transform(data_scaled)
# 4. t-SNE pour visualisation exploratoire
tsne_2d = TSNE(n_components=2, perplexity=30)
viz_tsne = tsne_2d.fit_transform(data_scaled)
# 5. Comparaison visuelle
fig, (ax1, ax2) = plt.subplots(1, 2)
ax1.scatter(viz_pca[:, 0], viz_pca[:, 1], c=clusters)
ax1.set_title('PCA - Variance préservée')
ax2.scatter(viz_tsne[:, 0], viz_tsne[:, 1], c=clusters)
ax2.set_title('t-SNE - Voisinages préservés')
```
**Cas pratiques concrets:**
| Situation | Choix | Raison |
|-----------|-------|--------|
| Segmentation clients bancaires (50k clients) | PCA | Scalabilité + interprétabilité pour régulation |
| Exploration de données génétiques (500 échantillons) | t-SNE | Structures biologiques non-linéaires |
| Dashboard temps réel e-commerce | PCA | Rapidité + reproductibilité |
| Publication recherche (clustering cellules) | Les deux | PCA pour méthode, t-SNE pour figures |
| Réduction avant ML (100k lignes) | PCA | Performance computationnelle |
**Erreurs à éviter:**
- ❌ Utiliser t-SNE pour des données très high-dimensional sans pré-réduction PCA
- ❌ Interpréter les distances absolues dans t-SNE (seuls les voisinages comptent)
- ❌ Utiliser PCA sur données non-normalisées
- ❌ Fixer perplexity=30 sans tester d'autres valeurs pour t-SNE
- ❌ Utiliser t-SNE en production sans considérer le temps de calcul
:::
::: {.callout-note icon=false}
## Question 3
Proposez une métrique business pour évaluer l'efficacité du clustering au-delà des métriques techniques.
:::
::: {.callout-note collapse="true"}
## Réponse Question 3
**Métriques Business pour Évaluer l'Efficacité du Clustering**
Les métriques techniques (silhouette score, inertie) mesurent la qualité mathématique, mais pas l'impact business. Voici des métriques orientées valeur:
---
**1. AUGMENTATION DU TAUX DE CONVERSION PAR SEGMENT**
**Définition:**
```
Taux conversion post-segmentation - Taux conversion baseline
─────────────────────────────────────────────────────────── × 100
Taux conversion baseline
```
**Exemple concret:**
```
Baseline (pas de segmentation): 2.5% conversion
Après segmentation et marketing ciblé:
- Segment Premium: 5.2% (+108%)
- Segment Économe: 3.1% (+24%)
- Segment Moyen: 2.8% (+12%)
Métrique globale: +45% conversion moyenne pondérée
```
**Avantages:**
- Mesure directe de l'impact financier
- Facile à communiquer aux stakeholders
- Comparable dans le temps
---
**2. CUSTOMER LIFETIME VALUE (CLV) PAR SEGMENT**
**Définition:**
```
CLV_segment = (Revenu moyen par achat × Fréquence d'achat × Durée de vie client)
- (Coût acquisition + Coût service)
```
**Application:**
```python
# Calcul après 6 mois de campagnes segmentées
segments_clv = {
'Cluster 0': {
'CLV': 1250€,
'Coût acquisition': 45€,
'ROI': 27.8
},
'Cluster 1': {
'CLV': 2100€,
'Coût acquisition': 85€,
'ROI': 24.7
},
'Cluster 2': {
'CLV': 890€,
'Coût acquisition': 35€,
'ROI': 25.4
}
}
# Métrique: CLV pondéré total vs approche non-segmentée
CLV_improvement = (weighted_avg_clv_segmented - clv_baseline) / clv_baseline
```
**KPI d'évaluation:**
- CLV moyen par segment > CLV baseline
- Variance du CLV entre segments (plus élevée = meilleure différenciation)
- Budget marketing optimisé selon CLV/segment
---
**3. TAUX DE RÉTENTION DIFFÉRENTIEL**
**Définition:**
```
Rétention_segment(t) = Clients actifs en t / Clients actifs en t-1
Métrique: Différence de rétention entre segments vs approche globale
```
**Tableau de bord:**
| Segment | Rétention M+3 | Rétention M+6 | Rétention M+12 | Amélioration vs baseline |
|----------------|---------------|---------------|----------------|--------------------------|
| Premium Jeune | 92% | 85% | 78% | +15% |
| Conservateurs | 95% | 91% | 88% | +22% |
| Mainstream | 88% | 79% | 71% | +8% |
| Baseline | 82% | 73% | 65% | - |
**Métrique synthétique:**
```
Score_Efficacité_Rétention = Σ(Rétention_segment × Poids_segment) - Rétention_baseline
```
---
**4. EFFICACITÉ OPÉRATIONNELLE DES CAMPAGNES**
**Définition:**
```
Coût par Acquisition (CPA) par segment
ROI marketing = (Revenu généré - Coût campagne) / Coût campagne
```
**Exemple d'évaluation:**
```
Campagne Email Marketing:
Sans segmentation:
- Envois: 100,000
- Taux ouverture: 18%
- Conversions: 450
- CPA: 22€
Avec segmentation (3 messages adaptés):
- Segment A: 35,000 envois, 28% ouverture, 280 conversions, CPA: 15€
- Segment B: 40,000 envois, 22% ouverture, 200 conversions, CPA: 18€
- Segment C: 25,000 envois, 32% ouverture, 220 conversions, CPA: 12€
Total conversions: 700 (+55%)
CPA moyen pondéré: 15.2€ (-31%)
Métrique: Efficacité = (700-450)/450 × (22-15.2)/22 = +90% d'efficacité
```
---
**5. INDICE DE STABILITÉ DES SEGMENTS (ISS)**
**Définition:**
Mesure si les segments restent cohérents dans le temps (crucial pour stratégie long-terme)
```python
def indice_stabilite_segment(labels_t1, labels_t2):
"""
Mesure la stabilité: clients restent-ils dans leur segment?
"""
# Matrice de transition
transition_matrix = pd.crosstab(labels_t1, labels_t2, normalize='index')
# Stabilité = moyenne des probabilités diagonales
stabilite = np.mean(np.diag(transition_matrix))
return stabilite
# Exemple
stabilite_3_mois = 0.87 # 87% des clients restent dans leur segment
stabilite_6_mois = 0.82
stabilite_12_mois = 0.76
# Métrique: Si stabilité < 0.7, les segments ne sont pas fiables
```
**Interprétation:**
- ISS > 0.80: Excellente stabilité, segments bien définis
- ISS 0.60-0.80: Stabilité acceptable, ajustements mineurs
- ISS < 0.60: Segments peu fiables, revoir la segmentation
---
**6. SCORE DE DIFFÉRENCIATION ACTIONNABLE**
**Définition:**
Les segments doivent être suffisamment différents pour justifier des actions distinctes
```python
def score_differenciation_business(segments_data):
"""
Mesure si les segments justifient des stratégies différentes
"""
scores = []
# 1. Différence de comportement d'achat
purchase_variance = segments_data.groupby('segment')['purchase_frequency'].var()
scores.append(normalize(purchase_variance.mean()))
# 2. Différence de préférences produits
product_affinity_diff = calculate_product_affinity_distance(segments_data)
scores.append(normalize(product_affinity_diff))
# 3. Différence de sensibilité prix
price_sensitivity_diff = calculate_price_elasticity_diff(segments_data)
scores.append(normalize(price_sensitivity_diff))
# 4. Différence de canaux préférés
channel_preference_diff = calculate_channel_divergence(segments_data)
scores.append(normalize(channel_preference_diff))
# Score final (0-100)
return np.mean(scores) * 100
# Interprétation:
# Score > 70: Segments très différenciés, stratégies distinctes justifiées
# Score 40-70: Différenciation modérée, personnalisation partielle
# Score < 40: Segments trop similaires, clustering peu utile
```
---
**7. MÉTRIQUE COMPOSITE: BUSINESS VALUE SCORE (BVS)**
**Formule intégrée:**
```
BVS = w1×(Lift_Conversion) + w2×(Amélioration_CLV) + w3×(Réduction_CPA)
+ w4×(Stabilité) + w5×(Différenciation)
Avec: Σwi = 1 (pondérations selon priorités business)
```
**Exemple de calcul:**
```python
# Pondérations pour un e-commerce
weights = {
'conversion_lift': 0.30, # Priorité maximale
'clv_improvement': 0.25,
'cpa_reduction': 0.20,
'stability': 0.15,
'differentiation': 0.10
}
metrics = {
'conversion_lift': 0.45, # +45%
'clv_improvement': 0.32, # +32%
'cpa_reduction': 0.28, # -28% (normalisé positivement)
'stability': 0.82, # ISS = 0.82
'differentiation': 0.73 # Score = 73/100
}
BVS = sum(weights[k] * metrics[k] for k in weights.keys())
# BVS = 0.456 → Score de 45.6/100
# Interprétation:
# BVS > 0.60: Clustering très efficace
# BVS 0.40-0.60: Clustering efficace
# BVS < 0.40: Revoir la segmentation
```
---
**DASHBOARD DE SUIVI RECOMMANDÉ:**
```
╔══════════════════════════════════════════════════════════════════╗
║ ÉVALUATION BUSINESS DU CLUSTERING - Q1 2025 ║
╠══════════════════════════════════════════════════════════════════╣
║ Business Value Score (BVS): 47.2/100 [✓] ║
║ ║
║ Métriques Détaillées: ║
║ ├─ Conversion Lift: +38% [✓] ║
║ ├─ CLV Amélioration: +28% [✓] ║
║ ├─ CPA Réduction: -22% [✓] ║
║ ├─ Indice Stabilité (6 mois): 0.79 [✓] ║
║ └─ Score Différenciation: 68/100 [✓] ║
║ ║
║ ROI Global Clustering: 324% ║
║ Coût implémentation: 45K€ ║
║ Gain annuel estimé: 146K€ ║
║ ║
║ Recommandation: ✅ Poursuivre et optimiser ║
╚══════════════════════════════════════════════════════════════════╝
```
---
**CONCLUSION:**
La meilleure approche combine:
1. **Métrique primaire**: Conversion Lift ou CLV (selon objectif business)
2. **Métrique secondaire**: Efficacité opérationnelle (CPA, ROI marketing)
3. **Métrique de contrôle**: Stabilité et différenciation
**Règle d'or**: Si le clustering n'améliore pas au moins une métrique business de 15-20% sur 3-6 mois, il faut revoir la segmentation ou son utilisation opérationnelle.
:::
## 8. Résumé et Bonnes Pratiques
::: {.callout-important icon=false}
## Checklist des étapes d'un projet de clustering
✅ **1. Compréhension du problème métier**
- Quel est l'objectif business ?
- Comment les clusters seront-ils utilisés ?
✅ **2. Exploration et prétraitement**
- Analyse des distributions
- Traitement des valeurs manquantes
- Normalisation/standardisation
✅ **3. Détermination du nombre de clusters**
- Méthode du coude
- Score silhouette
- Analyse de stabilité
✅ **4. Application des algorithmes**
- Test de plusieurs méthodes
- Ajustement des hyperparamètres
- Validation des résultats
✅ **5. Évaluation et interprétation**
- Métriques internes (silhouette, etc.)
- Visualisation (PCA, t-SNE)
- Profilage des clusters
- Interprétation métier
✅ **6. Déploiement et monitoring**
- Documentation des segments
- Mise à jour périodique
- Suivi de la stabilité des clusters
:::
## 9. Ressources Complémentaires
1. [Scikit-learn Clustering Guide](https://scikit-learn.org/stable/modules/clustering.html)
2. [Interactive Clustering Visualization](https://www.naftaliharris.com/blog/visualizing-k-means-clustering/)
3. [PCA vs t-SNE Explained](https://towardsdatascience.com/pca-vs-t-sne-257d2b9cc7cb)
4. [Customer Segmentation Case Study](https://towardsdatascience.com/customer-segmentation-using-k-means-clustering-d33964f238c3)
---
**Fichiers à rendre**:
1. Notebook Jupyter complet avec code et commentaires
2. Rapport d'analyse (1-2 pages) incluant :
- Méthodologie choisie
- Résultats obtenus
- Visualisations clés
- Recommandations métier